오늘은 여러 gpu 디바이스에서 분산 학습을 수행하는 방법을 정리해보겠습니다. 하기한 내용에 오류가 있을 경우 댓글 부탁드립니다.
How to parallel
Model parallel
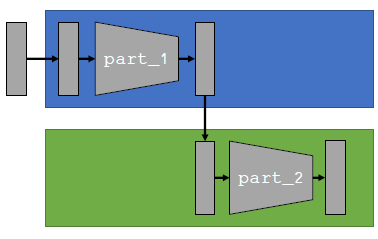
모델을 쪼개서 여러 gpu (병렬적)로 뿌려주는 경우입니다. model이 너무 커서 하나의 gpu 메모리가 충분하지 못할 때의 문제인 것 같습니다. 1번 디바이스에서는 전체 forward process의 part1을 맡고, 2번 디바이스에서는 part2를 맡는 방식으로 분산 학습이 진행됩니다. 간단히 코드를 작성해보면 아래와 같습니다.
class ModelParallel(nn.Module):
def __init__(self, *args, **kwargs):
super(ModelParallel, self).__init__()
self.part_1 = nn.Sequential(...)
self.part_2 = nn.Sequential(...)
# put each part on a different device
self.part_1.to(torch.device('cuda:0'))
self.part_2.to(torch.device('cuda:1'))
def forward(self, x):
x = x.to(torch.device('cuda:0'))
x1 = self.part_1(x)
x1 = x1.to(torch.device('cuda:1'))
y = self.part_2(x1)
return y
위와 같이 Model Parallel 방식은 모델을 여러 부분으로 쪼개고 각 디바이스에 할당해줘야 합니다. 그렇기에 각 모델에 맞게 어떤 부분으로 쪼개줄 것인지 지정을 매번 해줘야 한다는 번거로움이 존재합니다.
Data Parallel
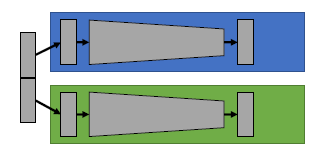
GPU 분산 학습에는 이러한 ModelParallel 이외에 Data Parallel 방식이 있습니다. 이번에는 모델을 여러 부분으로 쪼개는 것이 아니라, 데이터를 여러 부분으로 쪼개서 여러 GPU에 할당하여 병렬 처리해주는 방식입니다. 데이터가 매우 커서 하나의 GPU 메모리에 할당할 수 없을 때 유용합니다.
동일한 모델 카피를 떠두고, 각 다른 데이터 sub-batch를 각 카피에 넣어주는 형식입니다. 여러 개의 모델에서 병렬적으로 forward와 backward 과정이 이루어지기 때문에 반드시 동기화해주는 과정이 필요합니다. 즉, 다른 데이터를 forward하기 때문에 backward에서 gradient도 다르게 발생하므로 copy1에서 발생한 gradient를 copy1, copy2 모두에서 업데이트에 반영해야 하고 copy2에서 발생한 gradient를 copy1, copy2 모두에서 업데이트에 반영해야 합니다.
위의 Data Parallel 과정은 모델 구현과는 무관하기 때문에, Model Parallel과 달리 모델의 기존 구현 과정을 변형할 필요가 없습니다.
PyTorch Implementation of Data Parallel
nn.DataParallel
nn.DataParallel은 내부적으로 매 iteration마다, 모델 카피를 각 GPU에 올려주고 데이터 배치를 쪼개서 각 GPU에 할당해줍니다. 이후, forward와 backward 과정을 병렬적으로 수행한 후 모델의 업데이트를 동기화해줍니다.
model = MyModel()
model = nn.DataParallel(model) # make it parallel
nn.DataParallel의 경우에는 위의 코드 블락에 나와있는 것처럼 단순히 모델을 nn.DataParallel로 감싸주기만 하면 되기 때문에 매우 간편하다는 장점이 있습니다. 다만, 최적화가 되어 있지 않기 때문에 동기화 과정에서 오버헤드가 존재합니다. 예컨대, 동기화 시 각 디바이스의 결과를 수합하는 과정에서 하나의 GPU로 데이터가 모이게 되고, 그 과정에서 메모리 불균형이 발생하게 됩니다. 또한 멀티 프로세스가 아닌 멀티 스레드 방식의 병렬 처리를 지원하기 때문에 멀티 프로세싱에 비해 다소 느립니다.
DistributedDataParallel (DDP)

DDP는 nn.DataParallel과 달리 스레드 단위로 동작하는 게 아니라 프로세스 단위로 동작합니다. 따라서, 멀티스레딩이 아니라 멀티프로세싱이기 때문에 더 빠르게 동작이 가능하다는 장점이 있습니다.
DDP의 경우, 속도가 빠를 뿐 아니라 여러개의 머신에 확장이 가능합니다 (즉, gpu 클러스터에도 적용이 가능). 또한 병렬 처리 작업을 보다 유연하게 구성할 수 있게 됩니다. 다만, torch.multiprocessing.spawn 등의 약간의 코드 작업이 더 필요하다는 번거로움은 역시 존재합니다.
DDP 코드를 보기 전에 GPU 클러스터 구성에 대해 잠깐 짚고 넘어가겠습니다.
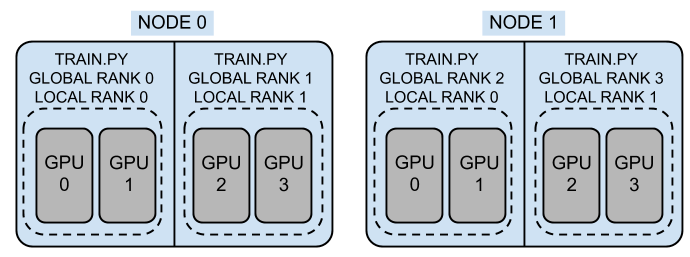
클러스터는 노드의 집합이라고 할 수 있습니다. 여기서 노드는 하나의 gpu 서버라고 보시면 좋을 것 같습니다. 위의 그림에서 클러스터는 2개의 노드로 구성되어 있고, 각 노드의 경우 4개의 gpu로 구성되어 있습니다. 하나의 프로세스(worker) 당 2개의 gpu가 할당되어 있고, 각 프로세스는 rank로 식별됩니다.
여기서, rank는 다시 global과 local 두 가지로 나뉠 수 있습니다. global rank의 경우에는 클러스터 전체 기준으로 해당 프로세스가 몇 번째 프로세스인지 식별하는 식별자입니다. 반면에, local rank의 경우에는 각 노드 내에서 해당 프로세스가 몇 번째 프로세스인지 식별하는 식별자입니다. 이러한 local rank 같은 경우에는, 기본적으로 모델을 gpu에 올릴 때나 데이터를 gpu에 올릴 때 사용하게 됩니다.
한편, 클러스터 전체를 world라고 칭하며, 클러스터 내부에 전체 몇 개의 worker가 있는지에 대해서 world size라고 칭하게 됩니다. 위의 그림에서는 world size는 4이며, global rank (혹은, world rank로 칭하기도 함)는 0,1,2,3이며 local rank는 각 노드 내에서 0,1의 숫자로 지정됩니다. 이처럼 local rank와 global rank를 별도로 할당하는 이유는 전체 world에 걸쳐 해당 프로세스를 식별하게 해주면서도, 각 노드 내 알맞은 gpu에 worker를 할당해주기 위함입니다.
위의 그림에서는 하나의 프로세스에 2개의 gpu가 할당되었지만, 관습적으로 하나의 프로세스에 하나의 gpu를 할당하곤 합니다. 이는 병렬화가 보다 잘 이루어지고, 입출력과 계산 비용 간의 balance가 잘 맞게 되기 때문이라고 합니다.
이제, DDP 코드를 살펴보겠습니다. ddp는 앞서 말씀드린 것처럼 데이터를 병렬화하는 작업입니다. 따라서, 모델을 DDP로 wrapping해서 모델 카피를 떠놓는 것뿐 아니라, DistributedSampler로 데이터를 프로세스 별로 쪼개서 각 프로세스에 할당하는 작업 또한 해주어야 합니다. 아래의 코드는 해당 작업을 구현한 부분입니다.
# train.py
def main_worker(local_rank, args):
# main_worker는 gpu id를 받게 되는데,
# 실질적으로 하나의 프로세스 당 하나의 gpu만을 할당 받으므로 gpu_id == local_rank가 됩니다.
# init the process in context
torch.cuda.set_device(local_rank)
world_rank = args.node_rank * args.ngpus_per_node + local_rank
torch.distributed.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:54263',
world_size, world_rank)
...
# wrap the model
model = nn.parallel.DistributedDataParallel(model, device_ids = [local_rank])
# use "distributed aware" sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=world_rank
)
loader = DataLoader(train_dataset, batch_size, shuffle=False, sampler=train_sampler)
def main():
args = parse_arguments()
torch.multiprocessing.spawn(main_worker, nprocs=args.ngpus_per_node, args=args) # only on mono-node
DDP의 경우에는 코드에 4가지가 고려됩니다.
1) 프로세스 뿌려주기 (spawning)
2) 프로세스 그룹 초기화
3) DDP로 모델 감싸주기
4) 분산학습을 위한 데이터 로딩
입니다.
1. 프로세스 뿌려주기
main함수에서 각 디바이스 간 통신을 가능케 하기 위해서 프로세스를 spawning해주는 작업이 필요합니다. 이때, torch.multiprocessing.spawn 을 사용하게 되는데, 어떤 함수를 멀티프로세스로 처리할 것인지, 프로세스 개수는 몇 개인지, 멀티 프로세스로 처리할 함수의 argument를 spawn함수의 인자로 넘겨주어야 합니다. 기본적으로 torch.multiprocessing.spawn은 클러스터 내 노드가 1개만 있는 상황에서만 동작하기 때문에, 프로세스 개수는 노드 내 gpu의 개수로 지정해주면 됩니다.
2. 프로세스 그룹 초기화
main_worker는 각 process가 수행할 함수를 의미합니다. main_worker의 경우에는 local_rank를 인자로 받게 됩니다. 이후, args에서 node rank (몇번째 노드인지 가리키는 식별자)와 노드 당 gpu 개수를 활용하여 local rank에서 world rank를 산출합니다.
이를 이용하여, torch.distributed.init_process_group에서 프로세스 그룹을 초기화해줍니다. 여기서, world_size와 world_rank를 인자로 받으면서 전체 노드에 걸쳐 프로세스를 식별할 수 있도록 합니다. 프로세스 그룹 초기화 시에는 cluster level로 값을 넘겨준다고 생각하면 쉽습니다.
3. DDP로 모델 감싸주기
다음으로 모델을 DDP 클래스로 감싸주게 됩니다. 이때, device_id는 local_rank를 넘겨주면 됩니다. 해당 클래스를 선언하는 것은 torch.distributed가 이미 초기화되어 있음을 가정합니다. 따라서, torch.distributed.init_process_group()을 통해 torch.distributed를 초기화해주지 않으면 에러가 발생합니다.
또한 DDP 클래스는 현재 하나의 gpu가 하나의 프로세스에 할당되는 경우만 지원합니다. 따라서 각 프로세스가 0부터 N-1번 gpu까지 하나씩 할당됨을 보장하기 위해서, main_worker 내에서 torch.cuda.set_device(local_rank) 등으로 프로세스 랭크 별로 gpu를 하나씩 할당하는 작업이 필요합니다.
4. DistributedSampler (데이터 로딩)
프로세스 별로 카피해둔 모델 인스턴스에 데이터를 로딩해주어야 합니다. 이는 DistributedSampler를 활용해서 넣어주면 됩니다. 이때, 프로세스의 개수(num_replicas), rank를 지정해주어야 해야하는데 이는 각각 world_size와 global rank를 지정해주면 됩니다. 각 인자에 대한 디폴트값으로는 현재 프로세스 그룹에서 world_size와 rank를 추론해서 넣어주게 됩니다. 즉, 디폴트로 알아서 world_size와 global rank가 인자로 들어가게 됩니다.
이후, DataLoader를 선언하면서 shuffle=False, sampler=DistributedSampler(...) 로 지정해주면, 분산학습을 위한 데이터 로딩 준비 작업은 끝이 납니다. 다만, DistributedSampler를 사용할 경우 에폭마다 각 다른 데이터를 뿌려주도록 명시해주는 작업이 필요합니다. 따라서, training loop에서 다음과 같이 코드를 추가해줍니다. 두번째 라인에서 train_sampler.set_ epoch(epoch) 부분입니다.
for epoch in range(start_epoch, opt.n_epochs):
train_sampler.set_epoch(epoch) # sampler가 동일한 data를 생성하는 것을 방지하기 위해
# reset gradients
optimizer.zero_grad()
_ = train(train_loader, model, criterion, optimizer, scheduler, epoch, opt)
dist.barrier()
if (opt.rank==0):
acc_score, _ = validate(val_loader, model, criterion, epoch, opt)
if (best_top1 < acc_score):
best_top1 = acc_score
print(f"Saving Weights at Accuracy {round(best_top1,4)}")
save_checkpoint(
{
'epoch': epoch,
'model': model.state_dict(),
'best_top1': best_top1,
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict()
}, os.path.join(opt.checkpoint_dir, opt.exp_name), f"vit_{epoch}_{round(best_top1, 4)}.pt"
)
print(f"Best Accuracy: {round(best_top1,4)}")
torch.cuda.empty_cache()
if opt.rank==0:
wandb.run.finish()
dist.destroy_process_group()torch.distributed.barrier()를 통해 프로세스 간 균형 맞추기
기본적으로, 병렬 처리 작업에서는 동기화 작업이라는 것을 거치게 됩니다. 각 프로세스의 결과를 취합하여 특정 연산을 수행 후, 다시 원래 작업을 재개하는 것이라고 간단히 이해하시면 될 것 같습니다. 예컨대, 분산 학습에서는 대표적으로 gradient 계산 후, weight update 시에 들어가는 gradient를 동기화하는 작업이 필요할 것입니다.
이처럼 동기화를 위해서는 각 프로세스가 특정 지점에서 모두 수합이 되어야 합니다. 이를 위해서는 작업을 빨리 끝낸 프로세스가 늦게 끝낸 프로세스를 기다려주는 작업이 필요한데 이를 수행하는 부분이 torch.distributed.barrier() 입니다. 특정 프로세스만 수행하는 작업 앞에라든지 혹은 epoch 시작지점 같은 부분에서 barrier를 적절히 걸어주어 각 프로세스 간의 균형을 맞춰주는 작업을 수행함으로써 병렬 처리를 보다 수월히 진행할 수 있습니다.
torch.distributed.barrier()를 적절히 걸어주지 않으면 각 프로세스 간의 균형이 깨져 데드락(각 프로세스가 서로의 작업 수행을 기다리다 교착 상태에 빠지는 것)이 발생하여 무한 대기에 빠지기도 합니다. torch.distributed.barrier()에 대한 예시는 위의 코드(dist.barrier로 표기)를 참고 바랍니다.
torch.distributed.launch 사용하여 분산 학습 수행
multi-process를 시작하는 방법은 다양한데, 그 중 torch.distributed.launch가 가장 널리 사용되는 방법입니다. 아까 말씀드린 torch.multiprocessing.spawn은 하나의 노드에서만 동작하는 것을 가정하기 때문에 multi-node로의 확장이 가능한 DDP의 이점을 온전히 활용할 수 없습니다. 따라서, 본인의 작업 환경이 멀티 노드 클러스터라면 torch.distributed.launch를 사용하여 분산학습을 수행하는 것을 고려해보는 것이 좋습니다.
아래의 코드는 torch.distributed.launch를 활용하여 분산학습을 수행하는 경우의 코드입니다. 다음과 같이 커맨드를 쉘에 입력해주면 됩니다. 아래는 2개의 노드를 가정하고 있습니다.
# On 104.171.200.62 (the master node)
python3 -m torch.distributed.launch \
--nproc_per_node=2 --nnodes=2 --node_rank=0 \
--master_addr=104.171.200.62 --master_port=1234 \
main.py \
--backend=nccl --use_syn --batch_size=8192 --arch=resnet152
# On 104.171.200.182 (the worker node)
python3 -m torch.distributed.launch \
--nproc_per_node=2 --nnodes=2 --node_rank=1 \
--master_addr=104.171.200.62 --master_port=1234 \
main.py \
--backend=nccl --use_syn --batch_size=8192 --arch=resnet152
# Output from node 104.171.200.62
Local Rank: 0, Epoch: 0, Training ...
Local Rank: 1, Epoch: 0, Training ...
# output from node 104.171.200.182
Local Rank: 0, Epoch: 0, Training ...
Local Rank: 1, Epoch: 0, Training ...
torch.distributed.launch를 사용할 경우에는 코드에 torch.multiprocessing.spawn을 포함하면 안된다는 점 참고 바랍니다(직접 테스트해보지는 않았으나, torch example document에 나와있는 사항입니다). torch.distributed.launch를 사용하는 경우에는 다음을 명령행으로부터 인자로 받아주어야 합니다.
- nprocs_per_node: 각 노드 내 worker 수를 정의. 각 노드의 GPU 개수와 일치해야 함.
- nnodes: 노드 개수 정의. two-node를 가정했으므로 2로 설정.
- master_addr, master_port: 마스터 노드를 위한 IP 주소와 포트 번호. 필수로 지정해주어야 함.
- node_rank: 노드의 rank 지정. 마스터 노드의 경우에는 0을 지정하고, worker 노드의 경우에는 1을 지정해주어야 함. 마스터 노드가 rank 0가 아니면, training이 진행되지 않음.
위의 인자에서는 명시적으로 world size, world rank, local rank가 주어지지 않습니다. 대신, n_procs_per_node, nnodes, node_rank 등의 파라미터로 유추해서 자동 지정이 되는 형태입니다. single node의 경우에는 nprocs_per_node 빼고는 입력하지 않으면 됩니다. 이외의 인자로는, 어떤 py 파일을 병렬 처리할 것인지와 그 py파일의 인자를 추가적으로 받게 됩니다.
torch.distributed.launch를 활용할 때에는 다음과 같이 실행하고자 하는 py 파일의 arguments에 local_rank를 파싱하는 부분을 추가해주어야 합니다. 이 인자는 launch.py (=torch.distributed.launch.py)에서 넘겨주는 인자로, 커맨드에서 추가 명시해줄 필요는 없습니다.
# train.py
import argparse
...
if__name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
...
args = parser.parse_args()
따라서, torch.distributed.launch를 활용하는 경우 최종 train.py는 다음과 같이 작성됩니다.
# train.py
import argparse
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
def main_worker(local_rank, args):
# init the process in context
torch.cuda.set_device(local_rank)
# Environment variables set by torch.distributed.launch
world_rank = os.environ["RANK"]
world_size = os.environ["WORLD_SIZE"]
torch.distributed.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:54263',
world_size, world_rank)
...
# wrap the model
model = nn.parallel.DistributedDataParallel(model, device_ids = [local_rank])
# use "distributed aware" sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=world_rank
)
loader = DataLoader(train_dataset, batch_size, shuffle=False, sampler=train_sampler)
...
torch.distributed.destropy_process_group()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
...
args = parser.parse_args()
main_worker(args.local_rank, args)보다 자세한 활용은, 실제 소스코드의 document를 참고 부탁드립니다.
torchrun
앞서 말씀드린 torch.distributed.launch이 가장 보편적으로 사용되고 있으나, torch.distributed.launch 같은 경우에는 곧 deprecated된다고 합니다. 대신 torchrun을 사용하라고 warning을 주고 있는데요, torchrun 같은 경우에는 torch.distributed.launch 보다 error handling이 잘되고 좀 더 유연하게 failure에 대응하도록 구현이 된 것 같습니다. 직접 사용해본 결과, 확실히 메세지 output 해주는 것 등이 좋다고 느꼈습니다. 또한, 기존 torch.distributed.launch는 local_rank 등을 직접 파싱해야 했으나, 여기에서는 환경 변수에서 읽어오는 형태입니다. 따라서, argument parsing하는 부분을 추가하지 않고 바로 os.environ['LOCAL_RANK']로 local rank를 assign할 수 있습니다.
# single node
torchrun --standalone --nnodes=1 --nproc_per_node=$NUMBER_OF_GPUS_PER_NODE \
main.py {args for main.py e.g. --arg1 --arg2 ...}
# multi-node
## On 104.171.200.62 (the master node)
torchrun \
--nproc_per_node=2 --nnodes=2 --node_rank=0 \
--master_addr=104.171.200.62 --master_port=1234 \
main.py \
{args for main.py e.g. --arg1 --arg2 ...}
## On 104.171.200.182 (the worker node)
torchrun \
--nproc_per_node=2 --nnodes=2 --node_rank=1 \
--master_addr=104.171.200.62 --master_port=1234 \
main.py \
{args for main.py e.g. --arg1 --arg2 ...}Summary
분산학습을 수행하는 경우는, model을 쪼개거나 데이터를 쪼개는 경우가 있습니다. 흔히, 데이터를 쪼개는 경우를 많이 활용하며 이 경우에는 torch.nn.parallel.DistributedDataParallel을 많이 활용합니다.
DDP를 활용하기 위해서는 여러 가지 추가 사항이 있는데, main_worker에서 프로세스 그룹을 초기화해주고, 모델을 DDP 클래스로 감싸주는 과정, 데이터 로더의 샘플러를 DistributedSampler로 변경해주는 과정입니다.
이 과정에서 인자를 노드 레벨(local)에서 주어야 하는지, 클러스터 전체 레벨(global)에서 주어야 하는지에 유의해야 하며, 클러스터의 노드가 하나일 때에는 global rank와 local rank가 동일해지므로 인자를 줄 때 크게 헷갈릴 일은 없을 것 같습니다.
마지막으로, 분산 학습 시에는 프로세스 간의 균형을 위해 dist.barrier()를 적재적소에 활용할 줄 알아야합니다.
References
- https://www.youtube.com/watch?v=TibQO_xv1zc
- https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
- https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html#torch.nn.parallel.DistributedDataParallel
- https://lambdalabs.com/blog/multi-node-pytorch-distributed-training-guide
- https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html
- https://github.com/pytorch/examples/blob/main/distributed/ddp/README.md
'DeepLearning > Pytorch' 카테고리의 다른 글
| [Pytorch] torch.no_grad() versus requires_grad=False (3) | 2023.11.13 |
|---|---|
| [Pytorch] 여러 gpu 사용할 때 torch.save & torch.load (feat. map_location) (0) | 2022.10.20 |
| [Pytorch] model.zero_grad() vs. optimizer.zero_grad() (0) | 2022.07.14 |
| [Pytorch] Learning Rate Scheduler 커스텀하기 (0) | 2022.05.26 |
| [Pytorch] 실험 재현(reproducibility)을 위한 실험 환경 randomness 제어하기 (1) | 2021.11.17 |