오늘 리뷰할 논문은 ICLR'23에 notable top 25%로 선정된 Unified-IO: A Unified Model For Vision, Language, And Multi-Modal Tasks 라는 논문입니다. 논문에서는 하나의 모델로 기존의 연구에서 다루던 task보다 많은 range의 task를 다루는 unified architecture를 제안합니다. 아이디어는 간단합니다. Encoder-decoder 구조를 통해 architecture에 있어서 unification을 이루면서도 다양한 input, output을 generate할 수 있게 모두 discrete tokenization을 통해서 architecture에 feed하겠다는 것입니다. 대략 30억개의 파라미터를 갖는 XL 모델을 pre-training을 거친 후 multi-task learning을 통해 학습시키고, evaluation을 진행한 결과 다양한 태스크에서 우수한 성능을 보여주었습니다.
하기한 내용에 오류가 있거나 궁금한 사항이 있으실 경우, 댓글 부탁드립니다!
1. Introduction
General-Purpose Systems
a single model that can handle “a variety of” tasks without task-specific settings, utilize large and diverse data corpora, effectively transfer concept knowledge across tasks, and even perform tasks unknown and unobserved at design and training time

Why is it challenging?
- Challenges that general-purpose systems face
- Heterogeneity among tasks: Tasks have incredibly diverse input and output representation (complicated to design input/output)
- There might be a key to this problem in NLP. In NLP, ...
- I/O is processed as a "sequence of discrete tokens."
- Sequence-to-Sequence architecture is applicable to a wide range of tasks.

How has it been handled?
Traditionally, multi-purpose systems are constructed based on task-specific heads. This limits the generality of systems (since this requires the model to train on new tasks when new tasks are added). More recently, with the emergence of unified architectures, modality-specific heads have replaced task-specific heads. These modality-specific heads might limit the supported tasks. In contrast, Unified-IO has no task- and modality-specific heads by discretizing all modalities.

Contributions
- Built a unified general framework covering various tasks embracing CV, NLP, and V&L domains.
- The first model to support all seven tasks in the General Robust Image Task (GRIT) Benchmark and obtains the top rank on the GRIT leaderboard.
- UNIFIED-IO evaluated on 16 diverse benchmarks across CV and NLP, w/o any fine-tuning towards any individual task, achieves decent performances compared to the current unified/single SOTA.
2. Vision, Language, and Multi-modal tasks.
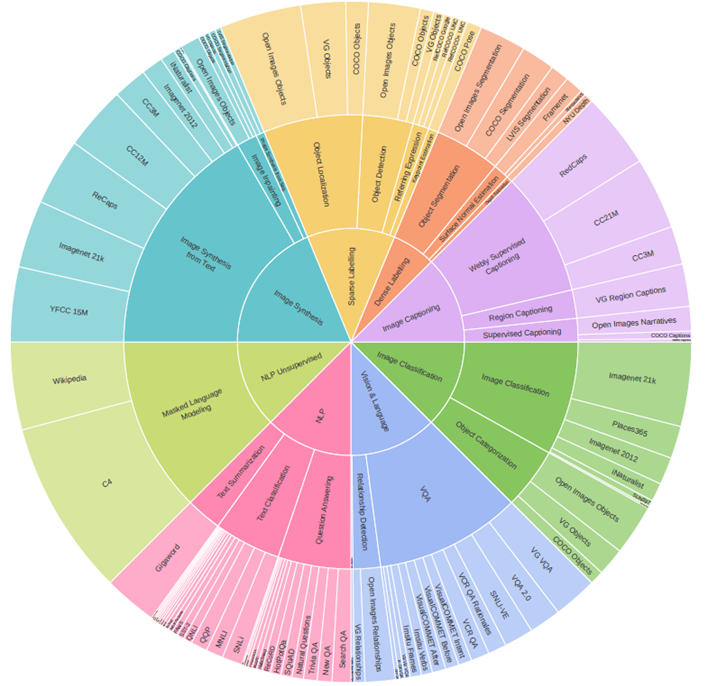
- 22 tasks grouped in 8 task groups
- 95 vision, language, and multi-modal datasets from 62 publicly available data sources as targets for the model to learn during multi-task training (Total 130M samples)
- Four types of modalities
- Text: natural language tokens
- Image: RGB images
- Sparse: a small number of location coordinates within the image
- Dense: per-pixel labels such as depth maps
Image Synthesis
Image Synthesis from the text
requires generating an image that matches a sentence

Image Synthesis from the segmentation
involves generating an image according to an input segmentation map

Image Inpainting
requires filling in a region of an image with a target object

Sparse Labeling
Object Detection
the input is a static prompt and an image, and the output text includes the bounding boxes and class names of all objects in the image.

Object Localization
requires returning bounding boxes around all objects of a given category. Under the situation that a given image does not include a query class, the output is an empty sequence.

Referring Expression Comprehension
requires the model to localize an image region described by a natural language expression. The annotation is similar to Object Localization, except that the target is specified with natural language expression instead of the class name.

Keypoint Estimation
requires returning the location of 17 keypoints on a human body for each person in an image.

Dense Labeling
Object segmentation
- Output: an RGB image with a black background and instances of that class filled in with unique colors. The binary masks here are built from each unique color.
-
Post-processing: Since the output image from UNIFIED-IO can have slightly non-uniform colors or extraneous background pixels, the output pixels are clustered by color, and connected components of less than 8 pixels are removed to build cleaned instance masks.

Depth Estimation
The output is a grayscale image representing the normalized depth at each pixel

Surface Normal Estimation
The output is an RGB representation of the x/y/z orientation of the surface at each pixel. The generated output image is resized to match the input image and converted back to r/g/b orientations to produce the final output.

Image Classification
Image Classification
During inference, compute the log probability of each class label in the evaluated dataset and return the highest-scoring one. This ensures UNIFIED-IO does not return a category from a different categorization dataset that is a synonym or hypernym of the correct label.

Object Categorization
identifies which label, from a given dataset, best corresponds to an image region defined by an input image and bounding box.

Image Captioning
Image Captioning

Region Captioning
a model generating a caption that describes a specific region in the image.

Vision & Language
Visual Question Answering

Answer-Grounded Visual Question Answering

Relationship Detection

NLP
Question Answering (Top), Text Classification (Middle), Text Summarization (Bottom)

Language Modeling (Mask Language Modeling)
- Included in both pre-training and multi-task learning to prevent catastrophic forgetting.
- Following T5, the mask language modeling objective randomly samples and then drops out 15% of tokens in the input sequence. All consecutive spans of dropped-out tokens are replaced by a single sentinel token. The target is to recover the dropped tokens given the sentinel token.

3. UNIFIED-IO
- Representation homogenization → Tokenization (Discretization)
-
Text representation
-
SentencePiece Tokenizer (following previous work)
-
Each task is given as a natural language prompt.
-
-
Images and dense structures representation
-
Dense labels are first converted to the image
-
Then, the image is discretized via VQ-GAN.
-
- Sparse structures representation
- 1000 Special location tokens added to represent discretized image coordinates.
-


- Pure Transformer : Encoder-Decoder → Seq2Seq of token sequence

Training
- Consists of two stages: pre-training and multi-task training
- Pre-training: uses unsupervised losses (masked language/image modeling)
- Multi-task training: trained on a massive multi-tasking dataset (8 task groups and 22 tasks)
Implementation Details
- The total vocabulary size: 49536
- Language: 32152
- Location: 1000 (for bounding boxes, body keypoints)
- Vision: 16384 (from VQ-GAN)
- Maximum # of tokens (I/O): 256 and 128 text tokens / 576 and 256 image tokens
- Patch sub-sampling: 128 image patches for pre-training and 256 out of 576 for multi-task stage.
- Adafactor optimizer to save memory
- Small, Base, and Large with batch size of 2048 and 1024 for XL
- 4-way in-layer parallelism and 128-way data parallelism to scale the 3B model training

4. Experiments
In the experiments, the paper presents results for
- UNIFIED-IO on the GRIT benchmark
- evaluation on the same concept and a new concept
- ablate training data via the GRIT ablation benchmark
- UNIFIED-IO evaluated on 16 other benchmarks in computer vision and NLP
- Prompt generalization on referring expression
Results on GRIT
GRIT
- An evaluation-only benchmark designed to measure the performance of models across multiple tasks, concepts, and data sources
- Task coverage: categorization, localization, VQA, refer expression, segmentation, keypoint, and surface normal estimation
Comparison with Baselines
- outperforms baseline in most cases
- For keypoint detection and surface normal estimation, slightly behind the baseline (Mask R-CNN, NLL-AngMF)
- Keypoint detection is followed by object localization
-
Image tokens from VQ-GAN were obtained solely from ImageNet-21K pretraining, including surface normal data might bring further improvement
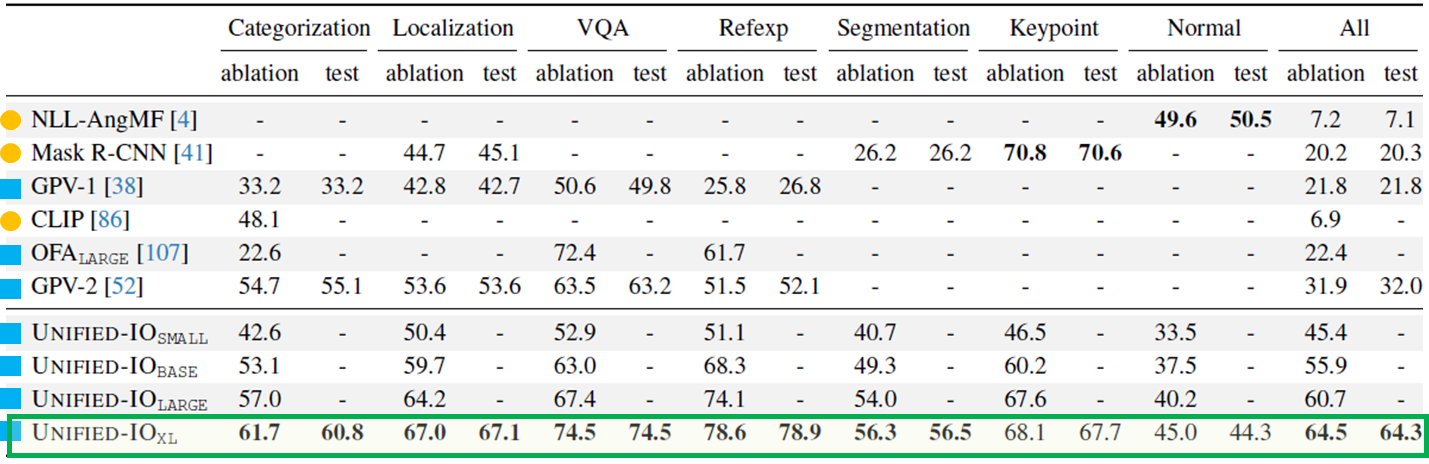
Evaluation of concept transfer
- same for samples that only contain concepts seen in the primary training data (a set of common datasets like COCO, ImageNet, and Visual Genome), and new for samples containing at least one concept unseen in primary training data.
- Little degradation after concept (class) transfer compared to competing entries
- The volume of training data provides almost as effective a level of supervision as provided by large standard vision datasets like COCO.
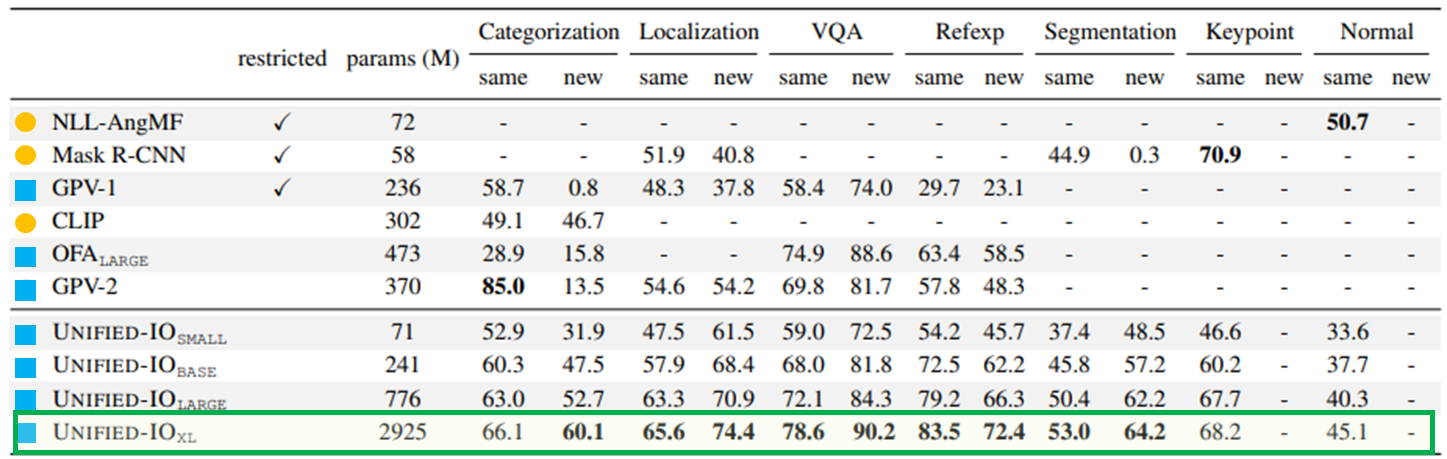
Ablation on task groups
Interruption among tasks is observed
- Removing the NLP group significantly boosts categorization
- Removing captioning also boosts performance on VQA and a few other tasks
Reciprocal interaction among tasks is also observed
- Removing image synthesis causes a significant regression in body keypoint detection and minor regression in localization and referring expression (sparse structures benefit from image synthesis)
- According to the inspection, the model predicts standing-human shaped keypoints even for people in different postures → Model relies on priors instead of the image content.

Results on Additional Tasks
- Not expect to get state-of-the-art results
- unfair to directly compare the models tailored to each task and a single jointly trained model
- Neither extensive task-specific tricks nor fine-tuning to the given task
- Despite being massively multi-tasked, UNIFIED-IO provides strong performance on these tasks
- Except for RMSE (Depth Estimation), the higher, the better.

Prompt Generalization Case Study
- Overall, the model has some capacity to generalize to paraphrases of the prompt
⇒ Row 3 works reasonably well despite using completely different words than training phrases - But some paraphrases result in a significant performance decrease (rows 5,6,7)
- Removing the spaces around the punctuation sometimes results in minor regression (row 0 vs. 1) and occasionally severe performance drop (row 6 vs. 7)
- Might be caused by the SentencePiece tokenizer
- The tokenizer possibly changes the tokenization of the referring expression if the quotation marks are not separated from it by spaces

5. Conclusion
Strengths
- The model performs extensive tasks with a single unified architecture.
- Simple yet effective.
- Well scaled up to massive data and parameters.
Weaknesses
- They argued that there is no modality-specific head, but the encoding and decoding process is still highly modality-specific (pre- and post-processing required).
- Interruptions between tasks have been observed.
- Technical novelty is somewhat weak, although the whole framework is new.
- Skill transfer was not fully discussed in the paper.