본 포스트는 "파이썬 머신러닝 완벽가이드" 책을 공부하고 정리한 글입니다.
아나콘다 환경을 설치한다면 사이킷런은 별도로 설치할 필요가 없기 때문에 colab 환경에서 실습을 진행하는 본 포스트에서는 별도의 패키지 설치는 하지 않겠습니다.
실습 colab notebook: colab.research.google.com/drive/1fDmXFwxTpDEGEbBA6Cu4T6QFbXz4UfSC?usp=sharing
1. 사이킷런 기본 모듈 설명
- sklearn.datasets: 사이킷런에서 자체적으로 제공하는 데이터셋을 생성하는 모듈
→ 솔직히 실습용 데이터셋 수준이기 때문에 많이 쓰이지는 않습니다. iris 등의 데이터셋이 있습니다.
- sklearn.tree: 트리 기반의 ML 알고리즘을 구현한 클래스를 모아놓은 모듈
→ 뒤이어 배울 Decision Tree, RandomForest 등이 구현되어 있습니다. 다만, ML 대회에서는 LGBM, XGB가 주로 쓰이기 때문에 주력 모델로는 많이 쓰지 않는 경향이 있습니다. 그래도 여러 모델로 앙상블을 할 때 서브 모델로 추가하기 좋습니다.
- sklearn.model_selection: 데이터를 train set, validation set, test set으로 분리할 때 혹은 최적의 하이퍼 파라미터를 서칭할 때 사용되는 모듈
→ 아주 많이 쓰이는 모듈입니다. train_test_split, 교차검증 혹은 grid search, random search 등이 구현되어 있습니다. 주로 모델을 만들고 평가를 하는 과정에서 많이 쓰입니다. (모듈 이름대로 model selection 시에 많이 쓰입니다)
2. Estimator 클래스, fit() & predict()
머신러닝을 활용해서 데이터 분석을 하는 경우에 전반적인 프로세스는 "데이터셋 분리 → 모델 학습 →예측수행 →모델평가"와 같습니다.
데이터셋 분리는 기본적으로 학습 데이터, (검증 데이터), 테스트 데이터로 분리합니다. 모든 데이터를 학습 데이터로 하여 모델을 적용시키기에는 모델이 학습 데이터에만 지나치게 적합하도록 학습될 수 있기 때문에, 모델 학습을 보다 일반적으로 적용시킬 수 있도록 데이터셋의 분리 과정은 필수적입니다.
모델 학습의 경우에는 학습 데이터 (train set)을 기반으로 머신러닝 알고리즘을 적용해 모델을 학습시키는 과정입니다. 예측 수행의 경우에는 학습된 ML 모델을 이용해 테스트 데이터의 분류 혹은 값 예측이 이루어지는 단계입니다. 마지막으로 평가는 이렇게 예측된 결과를 바탕으로 모델이 올바르게 학습되었는지(모델의 성능이라고 합니다)를 평가합니다.
Estimator 클래스는 머신러닝 알고리즘을 구현해놓은 것입니다. 사이킷런에서는 분류 알고리즘을 구현한 클래스를 Classifier로, 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭합니다. Classifier와 Regressor를 합쳐서 Estimator 클래스로 지칭합니다. 모든 Estimator 클래스는 fit()과 predict() 메소드를 내부에서 구현하고 있습니다. Estimator클래스를 모델 학습 단계에서 선언하고, fit 메소드를 활용하여 머신러닝 알고리즘을 실제로 데이터에 맞게 학습시킵니다.
(이를 설명할 수 있는 가장 간단한 예는 회귀분석입니다. 회귀분석은 간단하게 말해서 y = ax+b의 직선을 활용하여 관심있는 변수의 값을 예측하는 것입니다. LinearRegressor()라는 Estimator 클래스가 있다면, y = ax+b로 y값을 예측하겠다고 프로그램 상에서 선언을 하는 것이고 fit 메소드를 활용해서 a와 b를 실제로 예측해나가는 것입니다.)
predict 메소드는 예측 수행을 하는 과정으로, 실제 테스트 값을 집어넣어 예측값을 리턴해내는 단계입니다.
iris 데이터셋을 기반으로 설명을 드리겠습니다. iris 데이터셋은 4개의 설명변수(sepal length, sepal width, petal length, petal width)로, 하나의 종속변수(label)로 이루어져있습니다.
종속변수는 우리가 관심을 갖고 있는 변수, 혹은 값을 예측하고 싶어하는 변수라고 간단히 설명하겠습니다. 설명변수는 종속변수에 영향을 미치는 변수라고 생각하면 되겠습니다.
여기서는 그렇다면 sepal length, sepal width, petal length, petal width 4가지 변수를 활용하여 해당 붓꽃(iris)의 품종(label)을 예측하는 것을 하나의 task로 정의할 수 있겠습니다. label을 예측하므로, Classification 문제가 될 것입니다.
3. Model Selection
- 교차 검증
앞서 말했던 바와 같이 모델이 학습 데이터에만 과적합(overfitting)되는 경우를 방지하기 위해, 학습데이터와 테스트 데이터로 나누어 학습을 진행한다고 하였습니다. 그러나, 이 경우에도 고정된 학습 데이터와 테스트 데이터를 활용하여 모델에 대한 평가를 지속적으로 한다면 이역시 해당 테스트 데이터에만 과적합되도록 모델이 학습될 것입니다.
따라서 이러한 경우를 최소화하기 위해, 교차 검증을 진행합니다. 교차 검증은 주로 k 폴드 교차 검증을 의미합니다. k 폴드 교차 검증은 전체 데이터셋을 k개로 나누어 k번 학습을 진행하는 것입니다. 1번째 학습에서는 데이터셋의 첫번째 조각을 테스트셋으로, 나머지 조각들을 학습 데이터로 설정하여 학습을 진행합니다. k번째 학습에서는 데이터셋의 k번째 조각을 테스트셋으로, 나머지 조각들을 학습 데이터로 설정하여 학습을 진행합니다. 이를 도식화하면 아래와 같습니다.
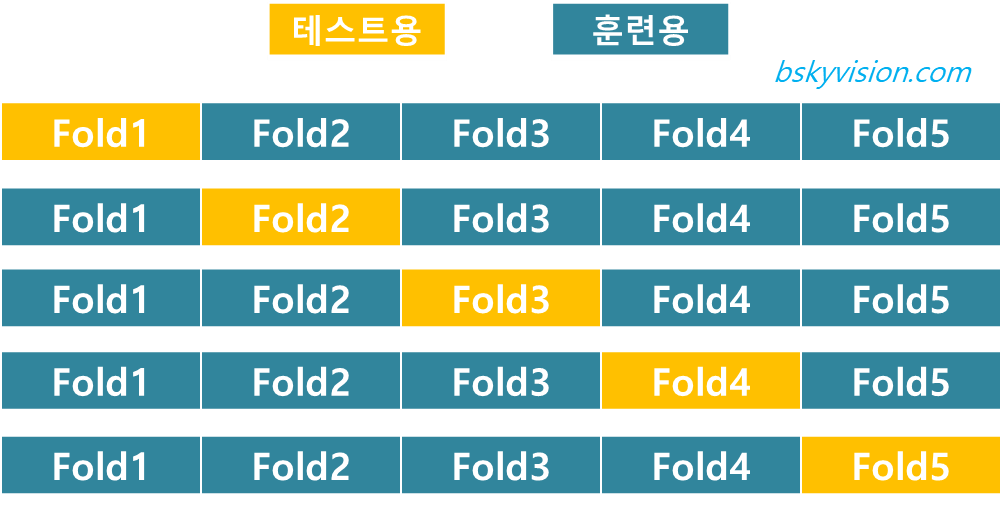
교차검증은 sklearn의 KFold에 구현되어 있으며, KFold 객체 생성 후에 split 메소드를 활용하여 train index와 test index를 각각 발생시키면 됩니다. (이때, k만큼 for loop 내에서 반복합니다)
- Stratified K 폴드
Stratified K 폴드는 imbalanced labeled data를 다룰 때 유용합니다. 즉, label1의 값을 갖는 데이터는 1000개이고, label2의 값을 갖는 데이터는 1개인 것과 같이 종속변수(target)의 분포가 불균형할 때 유용하게 사용됩니다. 이러한 타겟 분포가 불균형한 태스크는 대표적으로 Anomaly detection에서 많이 쓰이게 됩니다.
실제 타겟의 분포가 불균형할 때 데이터셋을 잘못 쪼개게 되면 어떤 label은 학습 데이터셋에 아예 속하지 않게 된다거나 하는 문제가 발생할 수 있습니다. 이에 레이블 분포가 불균형한 경우 레이블 분포에 맞게 계층적 K 폴드를 통해 데이터셋 분리를 진행한다면 이러한 문제를 해결할 수 있을 것입니다.
- cross_val_score()
굳이 train index, test index를 발생시키지 않고 바로 교차 검증 후 score를 리턴해주는 API입니다. 다만 scoring에 있어서 지원하는 평가 지표가 제한되어 있기 때문에, 앞의 KFold를 알아둘 필요는 있습니다. 또한 cross_val_score()는 레이블 데이터의 경우 알아서 stratified KFold 방식으로 분할합니다.
비슷한 API로는 cross_validate()이 있는데 이 경우에는 여러 개의 성능 평가 지표의 값을 리턴할 수 있습니다. 도한 수행 시간도 같이 제공합니다.
4. 데이터 전처리
Garbage In, Garbage Out과 같이 모델에 들어가는 데이터가 쓰레기라면 모델에서 내뱉는 예측값도 형편없을 것입니다. 따라서 입력 데이터를 정제하여 넣어주는 것이 매우 중요하고, 입력 데이터 정제 과정이 데이터 전처리라고 할 수 있습니다.
데이터 전처리가 필요한 예는 대표적으로 1) 결손값, 2) 텍스트형 데이터 처리 입니다.
1) 결손값
모델에서 null, NaN과 같은 값은 허용되지 않습니다. 평균값으로 대체하거나, 혹은 null값이 너무 많은 피처의 경우에는 아예 해당 피처를 날리는 것도 방법입니다. 평균값으로 대체하는 것 이외에도 여러 가지 방법으로 채워넣을 수도 있습니다. 가장 흔한 예는 클러스터링이나 knn 등을 통해서 값을 예측하는 방법입니다.
2) 텍스트
텍스트 데이터는 기본적으로 인식이 불가능합니다. 따라서 임베딩(수치화하는 것이라고 생각해둡시다)시키거나 혹은 텍스트를 라벨 인코딩을 통해서 숫자형으로 바꾸는 것도 하나의 방법입니다. 다만, 이 경우에는 텍스트라기보다는 텍스트로 표현된 카테고리형 변수인 경우에 적용이 가능할 것입니다.
텍스트 변수 또한 불필요한 피처라고 판단될 시 삭제하는 것이 좋습니다. 예를 들어 주민번호나 단순 문자열 아이디와 같은 경우에는 단순 식별자이므로 예측력에 큰 기여를하지 않기 때문에 삭제 가능합니다.
데이터 인코딩
머신러닝을 위한 인코딩 방식으로는 1) 라벨 인코딩 과 2) 원핫 인코딩이 있습니다.
1) 라벨 인코딩
사이킷런의 라벨 인코딩은 LabelEncoder 클래스로 구현합니다. fit을 통해 라벨의 unique값을 구하고 각 유니크한 라벨 당 인코딩 값을 부여합니다. 이후 transform을 통해서 각 label에 맞게 인코딩 값을 넣어줍니다. classes_ 속성으로 라벨의 유니크한 값을 구할 수 있습니다. inverse_transform을 통해 인코딩한 값을 다시 디코딩할 수도 있습니다.
라벨 인코딩 시 주의할 점은 문자열 값을 "숫자"로 변환한다는 점입니다. 즉 실제로 각 라벨 간의 대소 관계나 어떠한 위계도 존재하지 않지만 이를 숫자로 바꾸면서부터 "대소관계"가 존재하게 된다는 점입니다. 따라서 이러한 부분을 염두에 두고 사용하여야 합니다. 이때문에 LinearRegression과 같은 ML 알고리즘에서는 라벨 인코딩을 사용하지 않아야 하고, 반면 Tree based estimator의 경우에는 이러한 대소관계가 학습 시 고려되지 않으므로 라벨 인코딩을 사용하여도 무방합니다.
이러한 부분이 문제가 되는 것을 알고 원핫 인코딩으로 넘어갑시다.
2) 원핫 인코딩 (One-Hot Encoding)
원핫 인코딩은 숫자로 부여하는 것이 아니라 0,1만의 값을 갖도록 합니다. 예를 들어서 설명하자면, 과일이라는 종속 변수가 있다고 할 때 해당 변수의 값을 모아봤을 때 ["사과", "포도", "배", "귤"]로 정리가 된다고 가정합시다.
그러면 사과를 표현할 때 길이가 4인 벡터를 활용해서 표현합니다. (사과, 포도, 배, 귤 총 4개이므로) 또한 사과에 할당된 자리가 첫번째 자리라고 할 때 사과를 표현하면 [1 0 0 0]으로 표현할 수 있을 것입니다. 포도는 [0 1 0 0], 배는 [0 0 1 0] 으로 표현할 수 있을 것입니다.
파이썬에서는 pandas의 get_dummies()를 활용하면 됩니다. 이 경우에 사이킷런에서 지원하는 OneHotEncoder보다 더 간편하게 원핫인코딩을 수행할 수 있습니다.
'프로그래밍 > Python ' 카테고리의 다른 글
| [python] install error (disutil 관련) (0) | 2022.03.28 |
|---|---|
| [python] Counter (0) | 2021.12.09 |
| [Python] for ~ else (0) | 2021.12.09 |
| [python] getter, setter, property, decorator 정리 (0) | 2021.08.21 |
| Hyper parameter tuning (0) | 2019.08.15 |