오늘 리뷰할 논문은 CVPR 2022 oral로 선정된 페이퍼인 'MetaFormer is Actually What You Need for Vision'이라는 논문입니다. Vision task를 위해 실질적으로 필요한 것은 well-designed token mixer가 아닌 metaformer라는 transformer-like models가 공유하고 있는 추상화된 구조라는 주장을 하고 있습니다. 이를 위해 poolformer라는 아주 간단한 pooling operation을 통해 token mixing을 함으로써 실질적인 성능 기여는 well designed token mixer가 아닌 metaformer 구조 자체임을 보여주고 있습니다. 기존의 연구 방향이 어떤 token mixer를 사용해야 하고, 잘 개발하고자 하는 방향으로 흘러갔다면 이에 전면적으로(?) 반박하는 연구라고 할 수 있겠습니다. 하지만, 개인적으로는 transformer-like model이 성공한 이유에는 성능적인 측면도 있겠지만 data가 넘쳐나는 이 시대에 inductive bias을 최소화하고 데이터에만 의존하여 representation을 학습한다는 점, 규격화된 구조로 인하여 다른 modality로의 확장이 비교적 손쉽다는 점에서 그 의의가 컸다고 생각해왔던지라 2D 가정을 기반으로 한 poolformer를 통해 demonstration이 이루어졌다는 점에서는 아쉬웠던 것 같습니다.
후술할 내용에 오류 혹은 질문이 있으실 경우, 댓글 부탁드립니다!
Abstract
기존의 transformer 성공 뒤에는 attention-based token mixer module이 성능에 가장 많이 기여한다는 common belief가 있었음. 그러나, attention module을 다른 token mixer로 대체한 기존 연구들이 발표되면서 해당 논문은 기존의 common belief에 반하여, transformer 구조가 competent한 건 어떤 token mixer를 사용하느냐가 아니라 "metaformer" 구조때문이라고 주장함. 이를 보이기 위하여 token mixer로 아주 간단한 non-parameteric token mixer인 pooling operation을 사용하여 성능을 평가한 결과, 성능이 기존의 "well-tuned" token mixer based transformer 대비 성능이 매우 좋음을 알 수 있었음.
→ 이에 해당 논문은 "MetaFormer"의 컨셉을 제안하고 token mixer에 집중하는 게 아니라 이 metaformer의 구조를 발전시키는 것을 제안함.
1. Introduction

기존의 transformer encoder는 두 가지 요소로 나눌 수 있음. → attention으로 대표되는 token mixer (논문에서 이르길), 그 외의 channel mlp나 residual connection을 포함한 다른 요소들.
attention을 token mixer의 구체적인 한 형태라고 상정하면, 전체 transformer 구조는 Figure 1-(a)에서 볼 수 있듯이 metaformer로 나타낼 수 있음. 기존의 mlp mixer 계열의 구조들이 제안되면서 기존의 token mixer가 attention에 국한되지 않아도 된다는 가능성을 제기함. 이를 바탕으로 저자들은 metaformer 구조 자체가 중요하다는 가설을 제시하고, 이를 poolformer라는 non-parameteric pooling operation을 이용한 token mixer를 통해 이러한 가설이 실제로 valid함을 보여주고자 함. 논문은 실험을 통해 poolformer를 여러 vision task에서 높은 성능을 보임을 입증함.
2. Related work
Transformer는 NLP 분야에서 처음 제안되고 현재는 하나의 표준으로 자리잡음. 이를 Vision 분야에도 적용하여 ViT가 처음 제안되며, 이후에 경량화, shfited window 등의 컨셉을 도입하며 많은 attention 기반의 ViT-like model이 제안됨. 한편, Attention 기반 이외에도 MLP를 이용하여 token mixing을 수행하는 MLP-mixer가 attention 기반의 transformer보다 좋은 성능을 보임. 이후 어떠한 token mixer를 사용하는 것이 좋을지, SOTA 성능을 기록하기 위한 새로운 complicated token mixer를 제안하는 방향으로 많은 연구가 이루어짐.
그러나, 해당 논문에서는 기존의 연구 방향에 대한 의문을 던지고 transformer-like model이 성공한 데에는 어떠한 요소가 실질적인 영향을 미쳤는지에 대한 investigation을 수행함. 저자들은 metaformer라는 transformer-like model의 abstraction이 실질적으로 transformer-like model의 성능을 견인했다고 밝힘. 기존의 연구들 중에도 transformer-like model의 성능을 밝히고자 한 시도는 있었으나 metaformer와 같이 transformer-like model을 general한 concept으로 abstract하고 어떤 general framework의 측면에서 해석한 시도는 없었음.
3. Method
MetaFormer
Figure 1-(a)에서 나와 있듯이, input embedding (ViT의 patch embedding과 같은 작업)을 수행하고 metaformer block에 반복적으로 feed되는 구조임. metaformer block과 같은 경우에는 normalization → token mixer → norm → channel mlp 와 같은 구조를 취하고 있음. 또한, residual connection 역시 추가해주고 있음.
token mixer의 경우에는 기존의 attention 혹은 mlp가 될 수 있을 것이며 normalization의 경우에는 layer norm, batch norm 등이 추가될 수 있음. Attention 같은 경우에는 token mixer인 동시에 추가적인 channel mixing 연산도 수행한다는 점.
PoolFormer

논문에서는 metaformer framework에 average pooling을 token mixer로 활용하여 poolformer라는 구조를 만들어냄. poolformer가 좋음을 보여주는 것이 아니라 token mixing을 위해 별도의 설계 없이 아주 간단한 non-parametric pooling을 통해서도 준수한 성능이 나옴을 보여주면서 metaformer 구조 자체의 중요성을 보여주기 위함임.
pooling이 simple하다는 이유 이외에도 기존의 popular token mixer인 self-attention과 spatial MLP의 경우에는 토큰 시퀀스 길이에 complexity가 quadratic하게 증가하기 때문에 길이가 긴 시퀀스는 다루기 힘들지만 (특히, spatial mlp 같은 경우에는 token 개수가 증가할 수록 parameter도 증가하는 구조), pooling의 경우에는 시퀀스 길이에 따라 추가되는 parameter 없이 linear하게 complexity가 증가한다는 장점이 있음. 따라서, 이러한 pooling operation을 기반으로 hierarchical한 구조를 취하여 4개의 stage로 구성된 poolformer를 설계함.
자세한 구조는 아래와 같음.

- PoolFormer 구조에 대한 개인적인 생각
- 간단한 non-parametric pooling 구조라고는 하지만 실질적으로 블록 사이에 patch embedding을 반복적으로 끼워넣으면서 token mixing을 암묵적으로 수행하는 것으로 볼 수 있을 듯함. 좀 더 자세히 얘기하자면, poolformer에서 사용한 patch embedding은 convolution 기반으로, stride가 patch size보다 작음. 이렇게 될 경우에는, 기존의 transformer-like model에서 주로 가정하던 non-overlapping patch에 대한 가정이 사라지게 됨. 이렇게 되면, 결국에 각 패치는 실질적으로 특정 location에 대한 정보를 공유하는 구조임. Token mixing이 암묵적으로 수행된다고 볼 수 있을 것 같음. 이는 추후 ablation에서 전혀 의미 있는 token mixing이 이루어지지 않는 경우에도 어느 정도의 성능이 기록된다는 점에서 암묵적인 token mixing이 이루어진다고 볼 수 있을 것 같음.
또한, 실질적으로 convolution 필터 개수도 달라지면서 channel 축에 대한 projection도 이루어지는 것으로 보임 (물론, ablation에 따르면 이는 patch embedding이 가져오는 token mixing의 효과보다 더 적긴 함). - 이러한 점에서, 정확히 여기서 제안하는 metaformer의 컨셉이 정말 Figure1과 같다면, poolformer는 metaformer의 적합한 demonstration이 아니라는 생각이 듦. 또한, 기존의 transformer-like model의 대부분이 non-overlapping patches를 가정하고 있고 구조 자체의 flexible함이 장점이라고 생각이 드는데 이미지 데이터에 맞게 너무 많은 prior가 들어가 있지 않나라는 아쉬움이 듦. 그럼에도 불구하고 정말 metaformer의 컨셉이 norm → token mixing → (residual connection) → norm → channel mixing → (residual connection)의 블록 형태가 이어져있는 구조만을 의미하는 거라면, 위의 의문은 그냥 minor한 이슈로 볼 수 있을 것 같음.
- 간단한 non-parametric pooling 구조라고는 하지만 실질적으로 블록 사이에 patch embedding을 반복적으로 끼워넣으면서 token mixing을 암묵적으로 수행하는 것으로 볼 수 있을 듯함. 좀 더 자세히 얘기하자면, poolformer에서 사용한 patch embedding은 convolution 기반으로, stride가 patch size보다 작음. 이렇게 될 경우에는, 기존의 transformer-like model에서 주로 가정하던 non-overlapping patch에 대한 가정이 사라지게 됨. 이렇게 되면, 결국에 각 패치는 실질적으로 특정 location에 대한 정보를 공유하는 구조임. Token mixing이 암묵적으로 수행된다고 볼 수 있을 것 같음. 이는 추후 ablation에서 전혀 의미 있는 token mixing이 이루어지지 않는 경우에도 어느 정도의 성능이 기록된다는 점에서 암묵적인 token mixing이 이루어진다고 볼 수 있을 것 같음.
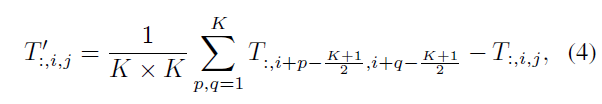
논문에서는 metaformer 구조 자체가 token mixer choice보다 더 중요하다는 점을 밝히기 위해 위와 같은 non-parametric pooling 연산으로 token mixing을 수행함. Pooling 연산 수식을 보면 자기 자신을 빼주는 걸 볼 수 있는데, 여기서 자기 자신을 빼주는 이유는 MetaFormer Block이 residual connection이 있기 때문이라고 주장함.
이에 대해 조금 더 생각해보면, 우리가 residual connection을 왜 하는지에 대해 조금 더 생각해보면 됨.
- 왜 pooling 연산 시 자기 자신을 빼주는 과정이 들어가야 하는지? 그게 무엇을 의미하는지?
- ResNet 논문[1]에서 처음으로 residual connection을 제안한 것은 층이 깊어지면 성능이 오히려 떨어지게 되는 현상을 방지하기 위함이었음. 이게 결국에는 자기 자신에 대한 정보를 그대로 유지하는 측면도 있지만, 논문에서는 mapping을 학습할 시에 어떤 함수 $f(x)$보다 $h(x)=f(x)-x$를 더 쉽게 학습할 것이라는 어떤 가설 하에서 residual mapping의 필요성을 주장하고 있음. 따라서, residual connection을 수행한다는 것은 결국에는 residual mapping $h$를 학습하는 것을 전제로 한다고 할 수 있음. 그러나, poolformer에서는 non-parametric token mixing을 수행하기 때문에 residual connection이 필요 없음. 오히려, pooling을 통과하면서 $g(x)$라는 자기 자신에 대한 정보를 유지하고 있는 aggregated representation을 returng하는데 $x$가 다시 더해지면서 오히려 정보의 중첩이 발생할 수 있음. Official repo의 discussion에 따르면, 실제로 subtraction을 해주는 경우가 성능이 조금이지만 더 좋았음을 알 수 있었음. 이러한 intuition이 실험적으로도 증명이 된 것으로 판단됨.
- 다만, residual connection이 이미 있기 때문에 자기 자신을 빼주어야 한다는 점에서 보았을 때 위의 operation은 살짝 의문을 불러일으킴. 추후 더해지는 $x$는 pre-norm 상태이지만, pooling operation에서 subtract되는 $x$는 post-norm이기 때문임. 따라서, 정보의 중첩을 막기 위해 $x$를 빼는 것은 semantic의 변화를 불러일으킬 수 있다는 의문이 들 수 있음. 이러한 부분을 laplacian kernel의 관점에서 조금 더 해석을 해볼 수 있음.
- Discussion에서 밝히길 위의 subtraction 과정은 결국에는 Laplacian kernel로도 해석이 가능하다고 말하고 있음. Laplacian kernel은 결국 특정 location에서 kernel size $K$만큼의 neighborhood에서 정보를 extract하는 과정임. 이러한 Laplacian kernel에서 layernorm은 결국 어떠한 정보도 변형시키지 않고 단순히 scaling만 이루어지게 됨. (이때의 scale factor는 $\frac{\gamma}{\sigma}$) 따라서 pool(norm(x)) - norm(x)의 연산은 결국에는 pool(x)-x에 linear함 (by scaling factor). 따라서, normalization을 거쳤는지에 대한 여부는 주변 neighborhood만의 정보를 가져올 수 있느냐 없느냐의 kernel 연산 수행의 기능을 방해하지 않게 됨. 앞서 말한 scaling factor를 고려했을 때 다음과 같이 residual connection을 표현할 수 있음.
x <- alpha*(laplacian(x)) + x - 여기서 $\alpha$는 $\frac{\gamma}{\sigma}$임. 앞서 말했던 것처럼 어차피 normaliztion은 다 cancel되고 $\alpha$ 텀만 남는다는 점. 결국 $\alpha$가 lapacian(x)와 x 간의 balancing을 수행해주는 역할을 하게 됨. 즉, 어느 정도로 x의 주변 정보를 최종 x에 반영할지에 대한 역할을 수행하게 되는 것임.
4. Experiments
크게 3가지 태스크(Image classification, Object detection & Instance segmentation, Semantic segmentation)에 대해서 성능 평가를 진행함. 성능 평가의 목적은 SOTA보다는 정말 poolformer 자체가 여러 task에서 competitive한 성능을 보여주는지에 초점을 맞춤.
4.1. Image classification
Setup
ImageNet-1K. data augmentation 적용, AdamW를 이용하여 300 에폭 동안 학습하고 weight decay는 0.05로 기존 ViT보다는 적 줌. learning rate scheduling (warm up for 5 epochs and later cosine schedule was applied) + label smoothing (0.1 of factor) + stochastic depth + layer scale 등의 regularization technique 을 활용함. dropout은 적용되지 않음.
또한, Layer Norm 같은 경우 기존의 layer norm은 channel dimension에 대해서만 통계량을 계산하지만 여기에서는 token과 channel dimension에 대한 통계량을 계산했다는 점 (즉, 여기에서도 token에 대한 정보를 활용한다는 점임 → 간접적인 token mixing이라고 볼 수 있을 듯)
Results


크게 ConvNet과의 비교를 수행하고, Attention과 spatial mlp token mixer를 사용한 metaformer 구조와의 비교를 수행하고 있음. poolformer의 경우 전반적으로 좋은 성능을 보일 뿐 아니라 같은 MACs (Multiply-accumulate operations)와 model size 하에서 baseline보다 더 높은 성능을 보여주고 있음. 이는 반대로 생각하면 같은 성능을 내기 위해 보다 적parameter가 필요하다는 점. naive한 token mixer를 사용하여도 기존에 sophiscated token mixer를 사용한 구조들보다 더 좋은 성능을 보였다는 점에서 중요한 것은 metaformer 구조 자체라는 것을 보여주고자 함. 한편, ResNet 구조와의 비교를 통해서 ResNet은 neural convolution이라는 더 높은 locality spatial aggregation 성능을 갖는 token mixer를 사용함에도 poolformer보다 좋지 못한 성능을 보였다는 점에서 metaformer concept 자체가 가져다주는 이점을 어느 정도 설명하고 있음.
4.2. Object detection & Instance segmentation
Setup
COCO benchmark. RetinaNet, Mask R-CNN 구조를 활용하여 backbone을 갈아끼우는 형태로 비교 실험을 진행함. baseline으로는 파라미터 수가 비슷한 ResNet 구조를 사용함. ImageNet-1K로 학습된 가중치와 함께 새로 추가된 부분은 Xavier init을 활용하여 가중치 초기화를 진행함.
Results

모든 경우에 baseline을 outperform하는 것을 확인할 수 있었음.
4.3. Semantic segmentation
Setup
ADE20K에 대한 실험. Semantic FPN 구조에 backbone을 갈아끼우는 형태로 비교. 가중치 초기화는 OD의 경우와 동일함. 베이스라인은 역시 비슷한 파라미터 수를 갖는 베이스라인으로 구성함. ResNet, ResNext, PVT (transformer 기반)을 베이스라인으로 활용함.
Results

semantic segmentation의 경우에도, token mixing을 위해서 pooling에만 의존하는 구조임에도 불구하고 poolformer를 backbone으로 사용한 경우가 competitive한 성능을 보여줌. 이는 역시 MetaFormer 구조 자체가 great potential을 갖고 있고 성능에 가장 많이 기여한다는 주장을 뒷받침해줌.
4.4. Ablation studies
classification에 대해 ablation을 수행함.

Token mixer
Table 5에 따르면, identity mapping과 global random matrix (fixed random weight → softmax 적용)를 사용함에도 불구하고 Top-1 accuracy의 손실이 baseline 대비 거의 없음을 알 수 있음. identity mapping과 global random matrix를 활용한다는 것은 결국에는 의미 있는 token mixing은 거의 이루어지지 않는다는 점인데 그럼에도 불구하고 매우 준수한 성능을 보여주고 있음. 이는 MetaFormer 컨셉 자체가 성능에 많은 기여를 한다는 주장에 힘을 실어줌.
→ 이 부분에 대해서는 조금 물음표인 게 과연 의미 있는 token mixing이 거의 이루어지지 않는데도 저렇게 성능이 나오는 게 가능한 걸까? patch embedding 과정에서 strided convolution이 이루어졌다는 점에서 token mixing의 효과를 얻었기 때문이 아닐까?
다른 token mixer에 대해서는 depth-wise convolution 적용(이 경우에는 depth-wise conv가 더 powerful한 token mixer이므로 조금 더 성능이 좋게 나옴), pooling size 변경 등의 시도를 추가했으나 성능에 큰 영향은 없었. Hyperparameter 등에 큰 영향 없이 token mixer를 뭘 쓰든 성능이 어느 정도 준수하게 나온다는 점을 미루어 보았을 때, MetaFormer 컨셉 자체의 중요성이 역시 demonstrate되고 있음.
Normalization
poolformer의 경우, token 간의 정보를 더 활용하는 MLN을 Normalization 방법으로 활용함. 이는 기존의 Layer Norm이나 Batch Norm보다 더 좋은 성능을 보임. 아예 Normalization을 제거하는 것은 학습 안정성을 저해하며 converge가 제대로 되지 않음.
Activation
ReLU나 SiLU로 대체하여 실험한 결과, 성능의 차이는 거의 없었음.
Other components
Residual connection과 channel mlp를 제거하는 실험을 수행함. 그 결과, 성능이 매우 떨어짐을 알 수 있었음. Residual connection 같은 경우에는 제거한 결과 성능이 0.1%로 random pick의 결과가 나옴. 즉, model이 유의미한 쪽으로 전혀 수렴되지 못함을 보여줌. channel mlp 역시 비슷한 결과가 나옴.
→ 여기서 또 궁금한 점은 channel mlp의 경우에는 제거했을 경우 성능이 5.7로 급감했으나 token mixer의 경우에는 identity나 random weight을 사용한다고 한들 성능 손실이 거의 없었다는 점에서 보았을 때 그럼 channel mixing이 미치는 영향이 token mixer보다 훨씬 크다는 점인가? 라는 의문이 듦.
Hybrid stages
앞서 밝힌 것과 같이 pooling은 token 시퀀스 길이에 크게 구애받지 않고 핸들링이 다른 token mixer 대비 쉬움. 반면, 다른 token mixer들은 global information의 aggregation이 쉬움. 앞 부분에 pooling을 배치하고, 뒷 부분에 attention과 spatial MLP를 배치한다면 효율적이면서도 효과적인 정보 aggregation이 이루어질 수 있을 것임.
이러한 intuition에 따라 stage에 따라 token mixer의 구성을 앞단에 pool, 뒷단에 attention or spatial MLP를 구성하였을 때 baseline에서 추가적인 성능 향상이 이루어졌음. 이는 pooling과 token mixer를 적절히 combine하는 방향으로 metaformer 구조의 모델들이 성능 개선을 이루어내는 방향으로 발전될 수 있음을 시사함.
5. Conclusion and future work
MetaFormer라는 transformer-like model의 abstraction을 제안하고 이를 poolformer라는 specific한 구조를 통해 보여줌. 이때, poolformer는 token mixer로서 매우 간단한 pooling operator를 활용하면서도 기존의 transformer-like model과 견줄 만한 성능을 보여주면서 결국 transformer-like model의 성능에 가장 큰 기여를 하는 것은 MetaFormer 구조 그 자체임을 입증함. 추후의 연구 방향으로는 poolformer를 self-sup 혹은 transfer learning 등 다른 학습 세팅에서도 활용 가능한지 탐구해볼 수 있으며 이러한 metaformer 컨셉이 nlp에도 valid한지 확인하는 과정으로도 이루어질 수 있을 것임.
Strengths
- metaformer라는 컨셉을 제안한 점. 기존의 mlp mixer 등을 통해 간접적으로 보여졌던 부분이 좀 더 확장되어 general한 concept 자체로 제안이 되었다는 점에서 그 의의가 큰 듯함.
- 아주 simple한 pooling 구조로도 성능이 기존 transformer-like model & resnet에 견줄 만한 정도로 뛰어난 성능이 나온다는 점.
Weaknesses
- poolformer라는 도구가 과연 기존 transformer-like model 대비해서 이미지라는 structure에 대한 prior가 너무 많이 가정되어 있는 것은 아닌지
- Transformer-like 모델의 경우, 물론 이미지에 맞는 inductive bias를 가정한 연구들 또한 많이 나오고 있으나 좀 더 generality를 추구하고 (vision이라고 특정해놓긴 했지만) 다른 modality와의 통합을 고려해본다면, 혹은 self-sup 등에서 masked image modeling 등에 잘 적용되려면 결국에는 구조에 있어서 규격화가 잘 이루어져야 한다고 보는데 metaformer 컨셉이 그러한 점은 고려하지 않는 것처럼 보임.
https://github.com/sail-sg/poolformer/issues/51
궁금했던 점에 대해 저자의 git issue에 질문을 했는데 hierarchical architecture에 막론하고(swin-T나 PVT 등 hierarchy를 가정하는 transformer-like model도 존재하기 때문에) metaformer 블록의 반복을 통해 metaformer라는 컨셉이 정의되며 실제로 poolformer에는 inductive bias가 기존의 transformer 모델보다 더 많이 담겨있다고 말하고 있다. 하지만 그럼에도 불구하고 ResNet보다 성능이 좋다는 점은 metaformer 구조 자체가 좋다고 말을 하고 있음.
