Emerging Properties in Self-Supervised Vision Transformers
이번에 리뷰할 논문은 2021년 ICCV에서 발표된 Emerging Properties in Self-Supervised Vision Transformers (Venue: Facebook AI Research)입니다. DINO라는 self-distillation 구조의 자기지도학습 방법론을 제안하며, 동시에 self-supervised learning과 ViT가 결합되며 발생하는 특성들에 대한 분석과 흥미로운 실험 결과를 논문에서 밝히고 있습니다. 특히 self-supervised ViT가 segmentation mask에 대한 정보를 갖고 있다는 특성이 굉장히 재미있었고, 기존의 supervised ViT 같은 경우에는 object boundary에 대한 정보를 직접적으로 얻을 수 없고 attention flow와 같은 추가적인 조작 방법이 들어가야 하지만 self-supervised ViT는 마지막 레이어의 attention head에서 직접적으로 해당 정보에 접근이 가능하다는 점도 재미있었습니다 (다만 이 경우에는 왜 그렇게 되는지에 대한 궁금증이 조금 남았던 것 같습니다). 하기할 내용에 오류나 질문이 있으시다면 말씀 부탁드립니다.
Abstract
self-sup 방법론을 ViT에 적용해서 잘 나오는 걸 넘어서, 다음과 같은 발견을 함
- self-supervised ViT features contain explicit information about the semantic segmentation of an image (supervised ViT나 convnets에서는 발생하지 X)
- these features are also excellent $k$-NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT.
- momentum encoder, multi-crop training, and the use of small patches with ViTs 역시 중요함을 강조함.
위의 finding을 DINO (self-distillation with no labels)라는 simple self-supervised method를 통해 implement함. ViT-Base 구조로 Top-1 linear probing accuracy를 80.1% 달성하면서 DINO와 ViT 간 시너지를 보여줌.
1. Introduction

Motivation
image-level supervision의 경우 label에 bound된 visual information을 주로 추출하게 된다는 점에서 이미지 내부에 있는 visual information을 온전히 얻어내지 못한다는 한계가 존재함. NLP에서 self-supervised learning이 성공하고 pretext task - downstream task의 training scheme이 dominate하게 됨. 이에 vision에서도 convnets을 바탕으로 self-supervised learning method가 개발되어 옴.
Observations
논문에서는 ViT를 self-supervised learning에 적용시키고 어떤 impact가 있을지에 대해 연구함. 이 과정에서 supervised ViT나 convnets에서는 발생하지 않았던 몇 가지 특징들을 발견함.
- self-supervised ViT에서 얻어낸 feature들은 scene layout (특히, object boundaries)에 대한 explicit한 정보를 포함하고 있음. 이 정보는 마지막 블록의 self-attention module에서 directly accessible함.
- self-supervised ViT feature는 어떠한 fine-tuning, linear classifier, data augmentation의 개입 없이 basic nearest neighbor classifier만으로도 잘 작동함을 알 수 있었음 (ImageNet에서 78.3%의 top-1 accuracy를 보여줌)
segmentation mask를 만들어내는 것은 self-supervised method 전반적으로 공유하는 특징으로 보이나, $k$-NN에서의 좋은 성능은 momentum encoder나 multi-crop augmentation 등의 특정 요소들과 결합되었을 때만 등장함. 또한, 작은 패치 사이즈의 ViT가 더 잘 working한다는 점도 발견함.
DINO
위 component의 중요성에 대한 발견을 바탕으로 label 없이 knowledge distillation을 하는 방향의 simple self-supervised approach인 DINO를 개발.
- directly predicting the output of a teacher network (built with a momentum encoder) by using a standard cross-entropy loss (no contrastive loss)
- can work with only a centering and sharpening of the teacher output to avoid collapse (w.o BatchNorm,
- DINO is flexible and works on both convnets and ViTs without the need to modify the architecture nor adapt internal normalizations.
small patch size ViT(Base)에 DINO를 적용했을 때 80.1%의 top-1 linear probing accuracy를 보여주면서 기존의 self-supervised feature들을 능가하는 성능을 보여줌. ViT뿐 아니라, ConvNets에 적용했을 때도 ResNet-50 아키텍처를 활용한 state-of-the-art 모델에 match되는 성능을 보여줌.
Computational resource & memory가 충분하지 않은 상황을 고려했을 때도 DINO가 valid & effective함을 보여줌 (take two 8-GPU servers over three days to achieve 76.1% on ImageNet linear benchmark, outperforming self-supervised systems based on convnets of comparable sizes with significantly reduced compute requirements)
2. Related work
Self-supervised learning
많은 연구가 instance classification (다른 이미지 = 다른 클래스, 이미지에 대한 augmentation을 줌으로써 같은 클래스를 만들어줌) 방식을 취함. 이 경우에는 명시적으로 classifier를 학습하게 되면 이미지 개수가 증가할 때 제대로 성능이 improve 되지 않는 문제가 발생함 (scale well with the number of images). 이에 noise contrastive estimator를 제안하면서 같은 클래스로 classify하는 것이 아니라 직접적으로 "compare"하는 형식을 취하게 됨. 이 경우에는 많은 이미지를 compare해야 효과적이다라는 단점이 존재하게 되는데, 이로 인해 배치 사이즈를 크게 가져가거나 memory bank를 두는 방식으로 이를 해결하고자 함. 몇몇 연구(e.g., SwAV)들은 clustering을 통해 instance를 grouping하는 방식을 많이 활용해옴.
최근 연구들은 unsupervised feature를 이미지 간 discrimination 작업 없이도 학습하는 방식을 제안하고 있음. BYOL의 경우에는 momentum encoder를 통해 얻은 representation을 matching하는 방식으로 이를 수행하고 있음. DINO의 경우에는 BYOL을 따라가지만, 다른 similarity matching loss를 사용하고 student와 teacher에 동일한 architecture를 활용함. → 이러한 점에서 DINO는 Mean Teacher self-distillation with no labels라고 할 수 있음.
Self-training and knowledge distillation
self-training: improve the quality of features by propagating a small initial set of annotations to a large set of unlabeled instances.
→ self-training은 hard label 혹은 soft label을 assign하는 방식으로 나뉠 수 있는데, 여기서 soft label을 활용하는 경우를 knowledge distillation이라고 함. Knowledge distillation 같은 경우에는 모델을 압축하기 위해 small netwrok가 larger network를 모방하는 방식으로 학습이 이루어짐. Noisy student에서 self-training에 distillation 방식을 사용할 수 있음을 보여줌 by propagating soft pseudo-labels to unlabelled data in a self-training pipeline (drawing an essential connection between self-training and knowledge distillation)
DINO는 이를 따라서 label이 아예 없는 상황에 knowledge distillation을 확장시켜 적용함. 기존에도 self-supervised learning과 knowledge distillation을 결합한 연구는 있었지만, 이들은 pre-trained fixed teacher에 의존함. 반면, DINO는 teacher 네트워크도 training 동안에 dynamic하게 training된다는 점.
이러한 점에서, knowledge distillation은 self-supervised pre-training의 post-processing step으로 쓰이는 것이 아니라 직접적으로 self-supervised objective로 이용되게 됨.
마지막으로, DINO는 codistillation과도 연관이 있는데 이는 student와 teacher가 동일한 구조를 가지고 training 동안 distillation을 수행하는 것임. 다만, DINO 같은 경우에는 teacher가 student의 momentum average로 update가 된다는 점에서 기존(teacher is also distilling from the student)과는 차별점이 있음.
3. Approach
3.1. SSL with Knowledge Distillation
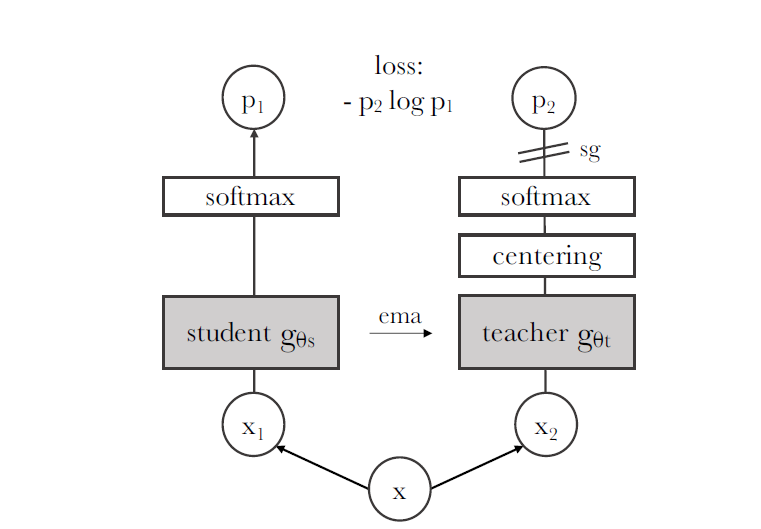

student network $g_{\theta_s}$와 teacher network $g_{\theta_t}$ 간의 output probabilities를 아래와 같이 matching하게 됨:
$$P_s(x)^{(i)} = \frac{\exp(g_{\theta_s}(x)^{(i)}/\tau_s)}{\sum_{k=1}^K \exp(g_{\theta_s}(x)^{(k)}/\tau_s)}$$
where $\tau > 0$ is a temperature parameter that controls the sharpness of the output distribution.
Teacher $g_{\theta_t}$를 fix시키고, 두 distribution을 match하는 방식으로 student network $g_{\theta_s}$를 업데이트하게 됨. 이때 $\theta_s$에 대해서 아래의 cross entropy loss를 계산하여 학습하게 됨.
$$\min_{\theta_s} H(P_t(x), P_s(x)),$$
where $H(a,b) = -alogb$.
DINO의 경우 SwAV를 따라 multi-crop augmentation을 적용하게 되는데, Augmentation set $V$는 두 개의 global view $x_1^g, x_2^g$ 와 global view보다 작은 해상도의 여러 local view를 포함하게 됨. Student network의 경우에는 모든 crop이 다 통과되지만, Teacher network의 경우에는 global view만이 통과되게 됨. 따라서, "local-to-global"의 correspondence가 encourage되는 형태임.
Multi-crop augmentation을 고려하여 objective를 수정하면 아래와 같음.
$$\min_{\theta_s} \sum_{x \in \{x_1^g, x_2^g\}} \sum_{x' \in V \\ x' \neq x} H(P_t(x), P_s(x'))$$
여기서, student network만 gradient descent를 통해 업데이트되고 teacher network의 경우에는 학습으로 인한 업데이트 과정 없이 student의 exponential moving average (EMA)임.
Teacher network
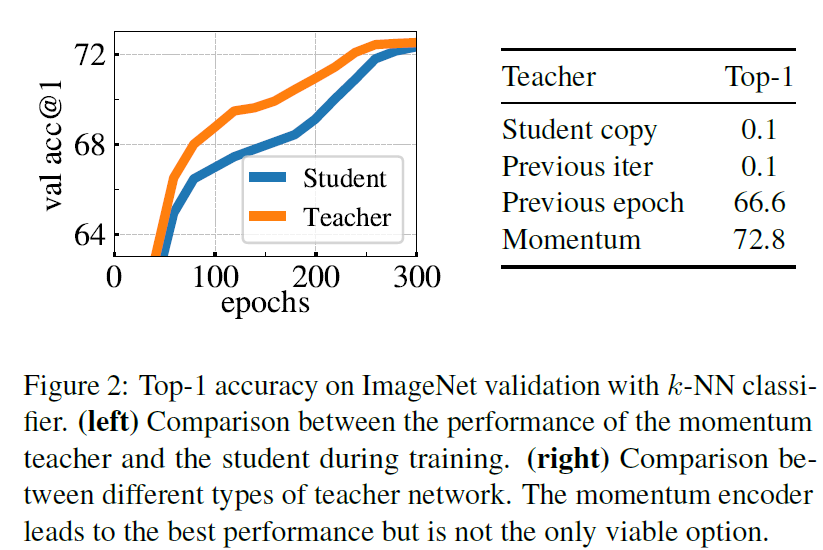
여기에서는 teacher network가 사전 지식을 가정하고 있지는 않기 때문에 그냥 teacher network를 sutdent network의 이전 iteration으로부터 update하는 방식을 취함. 실험을 통해 EMA 방식(momentum encoder)이 가장 낫다는 것을 알 수 있었음. → 단순 copy는 converge가 안되는 문제 발생.
EMA 시에 balancing parameter $\lambda$는 0.996부터 1까지 cosine schedule로 조정함. 기존에 momentum encoder를 쓴 건 contrastive learning에서 queue 대신 사용하는 측면에 가까웠지만, DINO에서의 momentum encoder는 그것보다는 self-training에서의 mean teacher에 더 가까운 의미를 가짐. 이러한 teacher 구성의 경우에는 exponential decay를 갖는 Polyak-Ruppert averaging과 비슷한 model ensembling 효과를 갖게 됨. Polyak-Ruppert averaging이 성능 개선의 효과가 있는 것처럼 DINO에서의 teacher도 student보다 성능이 더 좋았음
→ 따라서, 정말 distillation에서의 "teacher"로서의 기능을 하고 있음을 알 수 있음. (개인적으로 궁금했던 부분인데 이게 어느 정도 설명이 되는 것 같음.)
Network architecture
network $g$, backbone $f$, projection head $h$ → $g$ = $f \circ h$
Here, $h$ is implemented with a 3-layer MLP with a hidden dimension of 2048. $l_2$ normalization and a weight-normalized FC layer with $K$ dimensions follow the MLP.
BYOL과는 다르게, predictor를 따로 두지 않음. 따라서 teacher와 student가 exactly same해짐. 여기서 DINO를 ViT로 구현하게 되면, ViT 내부에는 BN이 없기 때문에 entirely BN free system를 구축할 수 있게 됨.
❓ Why BN free matters?
: BN에서 information leakage가 발생 → 치팅을 피해야 하니까 sync (global bn)나 shuffling 등의 귀찮은 과정을 거침 → 그런 부분을 vit backbone을 사용하면 충분히 없앨 수 있음 (대신 BN을 통해 얻을 수 있던 stability 문제를 다른 component로 해결해야 함).
Avoiding collapse
multiple normalizations를 통해 stabilize할 수도 있지만, momentum teacher의 centering과 sharpening만으로 model collapse를 방지할 수 있음을 확인함.
centering 같은 경우에는 하나의 dimension이 dominate하는 것을 방지할 수는 있으나 output distribution이 uniform distribution으로 collapse되는 것을 encourage하게 됨.
반대로, sharpening 같은 경우에는 output distribution이 uniform distribution으로 collapse하는 것을 방지할 수 있으나 오히려 하나의 dimension이 dominate하게 되는 쪽으로 이끌게 됨.
→ They counterpart each other. 두 개 다 쓰면 효과가 balancing된다. 따라서, 이 두 개만으로도 collapse를 방지하는 데 유의한 효과를 얻을 수 있음.
collapse에 대한 추가적인 실험을 supplementary에서 진행함.
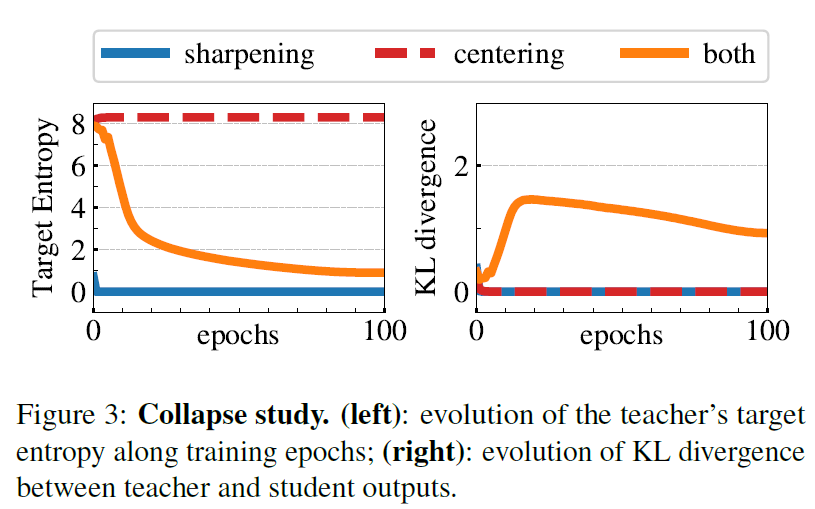
논문에서는, teacher와 student 간의 KL divergence 값이 0이 되는 경우 model은 결국 constant output을 내뱉게 되고, 이는 결국 collapse를 의미한다고 함 (KLD=0이라는 것은 결국, student가 teacher를 완벽하게 근사한다는 의미인데 이게 정말 잘 근사를 하는 게 아니라 shortcut에 빠진다는 걸로 해석할 수 있을 것 같은데 그래도 저 KLD 자체가 0이 된다는 의미가 그냥 collapse로 바로 이어지는 게 살짝 이해가 안감).
이 부분에서는 centering이나 sharpening 하나라도 없으면 KL=0으로 수렴하는 것을 보여주며 collapse가 관찰됨을 보여줌. 또한 여기서 centering (dimension으로 collapse하는 것을 방지하는 대신, uniform distribution으로 collapse하는 쪽으로 학습이 진행됨)이 적용되지 않았을 경우 Target Entropy $H(P_t)$가 0으로 수렴함. 이는 하나의 dimension으로 output distribution이 collapse되었음을 의미함. 반대로, sharpening(uniform distribution으로의 collapse를 방지하는 대신 하나의 dimension으로 collapse가 이루어질 수 있음) 없이 centering 만을 사용할 경우에 $H(P_t)$가 $-log\frac{1}{K}=8.3178 (K=4096)$의 값이 나옴. 즉, uniform distribution으로 collapse했음을 알 수 있음. 이처럼 centering과 sharpening은 서로 다른 양상의 collapse로 모델을 이끔을 알 수 있음. 따라서 이 두 가지 operation을 적절히 balancing함으로써 두 가지 양상의 collapse를 적절히 피할 수 있음을 어느 정도 보여줌.
→ 이 방식을 사용함으로써 stability는 조금 양보하더라도 batch에 대한 dependence를 ease할 수 있다는 점.
centering operation은 first-order batch statistic을 사용하는 구조로 teacher에 bias term을 더해주는 방식으로 기능할 수 있음. center term $c \in \mathbb{R}^K$ 역시 exponential moving average로 업데이트(online centering)되며 이러한 moving average를 적용함으로써 배치 사이즈에 상관 없이 잘 작동 가능함. (실제로 moving average를 적용하지 않는다면 현재 배치에서의 statistic에 매우 의존적일 것이며, 이는 결국 배치 사이즈에 대한 의존도로 이어질 수밖에 없음.)
$$ c \leftarrow mc + (1-m) \frac{1}{B} \sum_{i=1}^B g_{\theta_t}(x_i) $$
추가적으로, moving average 시 smoothing parameter $m$이 DINO의 학습 성능에 미치는 영향은 아래와 같음.
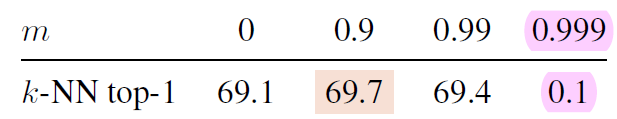
넓은 범위의 $m$에서 모델 convergence가 robust함을 확인하였지만, center $c$의 업데이트가 매우 느릴 때 (i.e., $m$=0.999), 모델 collapse가 발생함.
sharpening 같은 경우에는 teacher의 softmax에 적용하는 temperature parameter $\tau_t$ 값을 낮춰주는 방식으로 구현. 아래는 $\tau_t$의 값에 따른 모델 성능 변화를 관찰한 결과임.

0.06보다 높은 temperature를 적용할 때에 collapse가 발생했으나, 학습 초기에 작은 값으로 시작했다가 점차 temperature를 늘려가는 방식으로 진행한다면 0.06보다 높은 temperature를 사용하더라도 model collapse가 발생하지 않음을 확인할 수 있음. 추가적으로, $\tau_t$를 0에 수렴하는 값으로 설정하여 output distribution을 one-hot hard distribution ($\arg\max$)으로 만들어주었을 때에도 $k$-NN accuracy가 43.9로 나쁘지 않은 성능이 나왔음.
centering이 어떤 식으로 collapse를 방지하게 되는지에 대한 고찰
DINO의 깃 이슈를 보던 중 아래와 같은 이슈를 찾을 수 있었는데, centering이 정확히 어떻게 dominant dimension을 discourage하고 collapse to uniform distribution을 encourage하는지에 대한 질문이었음.
https://github.com/facebookresearch/dino/issues/101
Role of centering in preventing collapse · Issue #101 · facebookresearch/dino
I am not able to interpret the statement centering prevents one dimension to dominate but encourages collapse to the uniform distribution. Since we are subtracting the number and doing softmax, the...
github.com
나도 그냥 직관적으로만 받아들였던 터라 조금 더 elaborate하기 위해 작은 실험을 진행함.
실험을 하기 전, centering이 어떤 식으로 output distribution에 영향을 미치는지 생각을 해보면, centering의 경우에는 결국 채널 별 distribution (Batch size 크기만큼)을 zero-mean으로 shift하는 것. 이렇게 되면 mean의 절댓값이 큰 channel의 값이 0에 가깝게 보정이 되면서 channel에 대해 softmax값을 주었을 때 deviation이 조금 줄어들 것임.
이를 실제로 관찰하기 위해 5개의 벡터를 각기 다른 mean과 standard deviation을 따르는 정규분포에서 random sampling하여 생성해냄. 이때, sample 개수 (BatchSize)는 4로 설정함. 각 벡터를 channel 축으로 concat하여 samples라는 output tensor를 만듦. channel 축으로 concat했기 때문에 sample의 batch statistic이 각 채널 별로 다르게 잡힐 것(앞서 말한 mean과 standard deviation)임.

output tensor samples는 아래와 같음.

각기 다른 mean과 standard deviation을 따르는 정규분포에서 random하게 sampling하여 이를 channel 별로 concat. → batch statistic이 각 채널 별로 다르게 잡히도록.

center는 위와 같이 계산됨. 이를 samples에서 빼줌으로써 centered tensor를 얻음.

실제로 samples와 centered를 비교했을 때 mean의 scale이 극단적으로 크던 4번째 channel의 값이 어느 정도 보정이 많이 되었음. 그러나, 값의 scale이 크더라도 mean의 값은 작았던 (standard deviation이 1000으로 매우 컸기 때문에 큰 값이 sampling이 된 듯함) 5번째 채널의 경우 scale이 많이 줄어들지 않음. centering이 first-order statistic인 mean만 활용하기 때문에 standard deviation과 같은 second-order statistic의 효과까지는 보정하지 못하는 것으로 보임. Batch Norm에서는 이런 효과까지 보정이 가능했겠지만 여기서는 centering과 같은 1차 통계량 활용만으로도 충분하다고 말을 하고 있음.

samples와 centered에 softmax를 취해서 probability distribution을 계산함. 실제로 non-centered output에서는 값의 scale이 크던 4번째(1,2번째 sample)와 5번째 dimension(3,4번째 sample)으로 collapse가 발생했으나, centering 이후에는 어느 정도의 평탄화 작용을 하면서 이러한 collapse가 완화되었음을 확인할 수 있었음 (2번째 sample의 경우에는 1번째 dimension의 standard deviation이 크기 때문에 1번째로의 collapse가 이루어진 것처럼 보이지만 기존의 4번째 dimension으로의 collapse가 해소되었다는 점에서 centering의 효과를 확인).
이러한 centering이 recursive하게 적용될 경우에는 channel의 distribution이 uniform해지는 경향이 강해질 것임. 즉, uniform distribution으로의 collapse로 이어질 것을 짐작 가능함.
3.2. Implementation and evaluation protocols
Vision Transformer

original ViT paper와는 달리 패치 사이즈를 8로 작은 패치 사이즈를 추가적으로 적용해봄.
Implementation details
- ImageNet-1K에서 학습
- AdamW with a batch size of 1024
- distributed over 16 GPUs when using ViT-S/16
- Learning rate ramp-up applied during the first 10 epochs to its value determined with the following linear scaling rule: lr = 0.0005 * batchsize/256
- learning rate decay: follows a cosine schedule from 0.04 to 0.4
- temperature $\tau_s$ = 0.01, $\tau_t$ = 0.04 to 0.07 (linear warm-up during the first 30 epochs)
- followed data augmentations of BYOL (color jittering, Gaussian blur and solarization) and multi-crop with a bicubic interpolation to adapt the position embeddings to the scales.
Evaluation protocols
- 기존의 standard protocols: linear probing on frozen features or to finetune the features on downstream tasks
- linear probing 같은 경우 training하는 동안 random resize crop과 horizontal flips augmentation을 적용함. fine-tuning 같은 경우에는 pretrained weights로 초기화한 후에 adapt.
- 그러나, 기존의 protocol은 learning rate과 같은 hyperparameter에민감하다는 단점이 존재함.
- 따라서, 논문에서는 simple한 $k$-NN classifier로 feature의 quality를 추가적으로 평가함. downstream task의 training data를 frozen model에 feed해주고 feature를 저장함. 이후, test 이미지의 feature에 대한 $k$개의 nearest neighboring feature의 label의 majority를 test image의 label로 예측하는 형태.
- hyperparameter tuning이나 data augmentation이 필요없다는 점, downstream dataset에 한 번의 forward 과정만으로도 run할 수 있다는 점에서 feature evaluation을 간단히 했다고 말할 수 있음.
4. Main Results
800 epochs 동안 학습시킨 결과를 report (BYOL은 제외. BYOL은 300 epochs 이상 학습시키면 오히려 성능 저하가 발생하여 300 epochs 동안 학습 시킨 결과를 report)
4.1. Comparing with SSL frameworks on ImageNet
Comparing with the same architecture

RN50과 ViT-S를 기본 구조로 선정하여 여러 self-sup 방법론들과의 성능 비교 수행. DINO가 성능이 더 잘나옴. 이러한 성향은 ViT 구조일 때 더 두드러짐. 특히, DINO가 ViT와 결합할 경우에는 $k$-NN accuracy가 타 방법론 대비 월등하며, linear probing의 결과에 필적하는 정도로 성능이 높게 나옴 (74.5 vs 77.0)
Good $k$-NN classifier라는 특성은 다른 self-sup 방법론이나 ResNet에서는 나타나지 않음. only DINO + ViT
Comparing across architectures
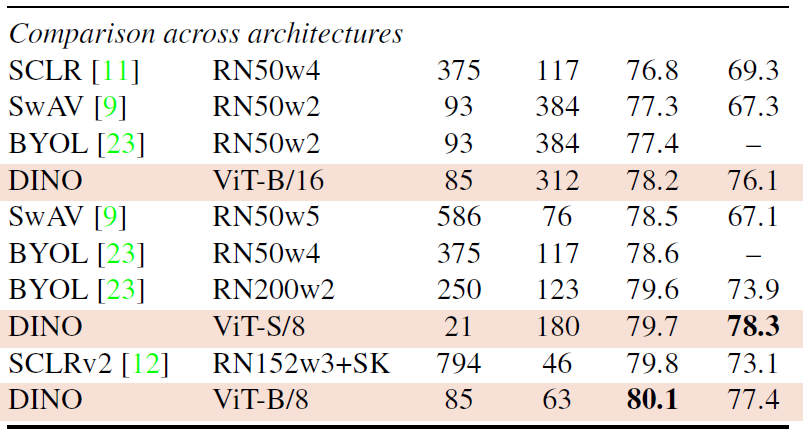
이 부분은 방법론들 간의 직접 비교가 주목적이 아닌, 아키텍처의 크기가 커질 때 ViT + DINO의 성능 한계를 평가하기 위함임.
실제로 성능을 평가해본 결과, DINO의 경우 ViT의 parameter 수를 키우는 것보다 (모델 스케일을 키우기보다) 더 작은 패치 사이즈를 사용하는 것이 성능 향상에 더 많은 영향을 주었음.
그러나 작은 패치 사이즈를 사용할 경우 파라미터를 추가하지는 않지만, running time을 감소시킬 뿐 아니라 (여기서 말하는 running time 감소는 throughput 감소를 얘기하는 듯) 많은 메모리 사용량을 야기함. 그럼에도 불구하고 ViT-B/8을 사용한 DINO의 경우에는 기존의 SOTA보다 linear probing 80.1% $k$-NN accuracy 77.4%로 좋은 성능을 보여줄 뿐 아니라, 10배 적은 파라미터를 사용하면서도 1.4배 빠른 runtime을 보여주고 있음.
4.2. Properties of ViT rained with SSL
4.2.1. Nearest neighbor retrieval with DINO ViT
이미지넷 분류에서 $k$-NN accuracy가 높게 나옴 → What about tasks based on nearest neighbor retrieval?
Image Retrieval

feature freeze하고 $k$-NN retrieval을 image retrieval datasets에 수행한 결과, supervised 대비 성능이 잘 나옴. ImageNet이 아니라 large scale retrieval dataset에 pretrain시킨 결과 (저자들은 self-supervised learning은 label 없이 pretrain을 진행하기 때문에 다양한 데이터셋에 사전학습하기 용이하다고 밝히면서 이 데이터에서도 pretrain했다고 함), 기존의 off-the-shelf feature 기반의 방법론 중 가장 좋은 성능의 방법론과 비교했을 때 이를 선회하는 결과를 보여줌.
Copy Detection
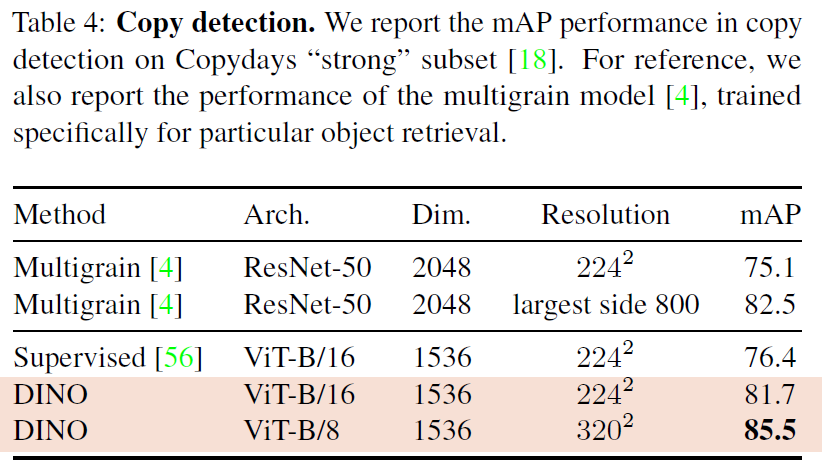
copy detection task (blur, insertions, print and scan 등을 거친 이미지를 인식하는 작업)에서 ViTs with DINO가 잘 동작하는지 실험해본 결과, competitive한 결과를 얻음. 실제로 object retrieval 태스크에 학습한 모델 대비해서 더 좋은 결과를 얻음.
4.2.2. Discovering the semantic layout of scenes
Video instance segmentation

연속되는 프레임 간의 nearest neighbor를 찾아 scene을 segment하는 방식으로 fine-tuning이나 추가적인 레이어 학습 없이 DAVIS 2017 데이터셋에서 video instance segmentation을 수행함. DINO의 training objective나 아키텍처가 dense task를 위해 설계되지 않았음에도 불구하고, 벤치마크에서 성능이 competitive하였음. 네트워크가 fine-tuning을 거치지 않았음에도 이처럼 준수한 성능을 얻은 것을 보았을 때, DINO 모델의 출력이 어느 정도 spatial information을 담고 있을 수밖에 없음. 추가적으로, 작은 패치 사이즈가 해당 dense recognition task에 더 잘 작동함을 확인할 수 있었음.
Probing the self-attention map


Figure 3에서 DINO의 각 head에서 각각 다른 semantic region을 attend하고 있음을 확인할 수 있음 (가려지거나 매우 작은 부분까지 잘 포착). 또한, Figure 4에서는 supervised 대비 DINO가 훨씬 object를 잘 attend하고 있음을 알 수 있음. 실제로 attention을 활용해 masking을 생성(이 mask는 오롯이 self-attention maps에서 추출되었고 mask를 optimize하는 과정이 일절 없음)하여 정답 mask와 jaccard similarity를 계산한 결과 DINO가 supervised 대비 훨씬 높은 유사도를 보임. 이러한 segmentation 정보는 self-supervised convnets도 보이는 특성이지만 이러한 정보를 추출하기 위해 복잡한 과정을 거쳐야한다는 점.

이러한 object mask awareness는 단순히 DINO만의 특징이 아닌 self-sup ViT에서 다 arise되는 특성임을 알 수 있음 (또한 multicrop에서 기인되는 특징도 아님. 참고로 다른 self-sup 방법론들 역시 ViT에서 다시 training을 수행함)
🔍추가적인 Attention map visualization


Figure 8은 reference point에서의 self-attention map visualization을 표현한 것인데 같은 이미지더라도 다른 point에서의 attention map을 visualize하면 다른 부분을 좀 더 attend한다는 것을 알 수 있었음. (아마 구현은 cls token에 대한 attention map 말고 reference point에 대응하는 패치의 attention map을 가져오지 않았을까 생각됨 → 이런 부분에 있어서는 패치 간의 relationship도 잘 보고 있는 것 같은데 selfpatch나 what do self-supervised vit learn 같은 경우에 attention map collapse가 일어난다는 분석이 나온 게 좀 궁금하긴 하다)
4.2.3. Transfer learning on downstream tasks

다양한 downstream task에 fine-tuning하여 transfer learning 수행. 동일한 아키텍처(ViT)이지만 이미지넷에서 supervised pretraining을 거친 모델과의 비교를 했을 때 더 좋은 성능을 보임. self-sup feature가 sup feature 대비 더 transfer가 잘되는 것은 convolutional networks에서부터 관찰된 결과와 consistent.
5. Ablation Study of DINO
Importance of the Different Components

각 모델은 모두 ViT-S/16으로 300 epoch 동안 학습시킴.
- momentum이 없으면 모델이 converge하지 못함 ($k$-NN과 Linear accuracy가 모두 0.1로 random pick 수준이 나옴)
- Sinkhorn-Knopp 알고리즘은 SwAV에서 collapse를 막기 위해 쓰였으나, 실제로 DINO에서는 momentum이 있어 큰 효과가 없었음. 따라서 최종 아키텍처에서는 삭제. (row 3 vs. 9)
- DINO에서 multi-crop training과 cross-entropy가 매우 중요한 역할을 함을 확인할 수 있었음 (row 4,5)
- Student network에 predictor를 더하는 것 역시 BYOL에서는 중요한 역할을 했으나 DINO에서는 큰 역할을 하지 않음.
Importance of the patch size

작은 patch size가 consistent하게 성능($k$-NN acc) 향상에 좋은 영향을 미치는 것으로 확인됨. 그러나, 작은 패치 사이즈를 사용한다고 해서 파라미터 수가 증가하지는 않으나 throughput 감소를 야기함.
Training with the small batches

작은 배치 사이즈로도 어느 정도 높은 성능을 낼 수 있다는 것을 보여줌. (근데 왜 multi-crop 없이 했는지..?흠)
Longer training

Self-Supervised ConvNet의 경우와 비슷하게 DINO의 경우 학습을 더 시킬 수록 성능이 증가함. 그러나, BYOL은 예외였음 (300 epoch이 최고 성능).
6. Conclusion
Strengths
- ViT를 성공적으로 self-supervised learning에 적용시킴.
- batch norm 없이 centering 등의 1차 batch statistic만을 활용하여 collapse를 방지함. 이를 통해 batch에의 dependency를 감소시킴.
- good nearest neighbor retrieval performance.
- self-supervised ViT에서 emerge하는 특징 분석이 잘됨. (semantic segmentation, object boundary)
- 상대적으로 적은 computational requirements
- 작은 배치 사이즈로도 성이 준수하게 나옴.
Weaknesses
- technical novelty는 떨어짐.
- 조금 떨어지는 training stability (training dynamics를 관찰해본 결과, 실제로 loss logging 과정에서 dip이 발생함.)
논문에서는 self-supervised ViT가 specially designed ConvNets에 견줄 만한 성능을 냈다는 점을 의의로 꼽고 있음. 또한, future application에 대한 방향으로 이미지 검색 관련 task (이게 실제로 내 연구에 활용된 방향이기도 함!), weakly supervised image segmentation에 대한 weak label로서 DINO의 scene layout에 대한 정보를 사용할 수 있다 라고 얘기하고 있음. 개인적으로는 후자에 대한 intuition은 생각해보지 못하고 있었는데 좋은 방향이겠다 싶었음.