경사하강법을 얘기하기 전에 최적화란 개념에 대해 먼저 짚고 넘어갈 필요가 있다. 최적화는 간단하게 말해서 고등학교때 배우는 함수의 극대 극소지점을 찾는 것이다 (그래서 우리가 그렇게 미친 듯이 미분해서 0이 되는 지점을 찾는 문제를 풀었던 것). 즉 함수를 최소화 하거나 최대화하는 것을 의미한다. 이때의 함수를 우리는 목적함수라고 부른다. 머신러닝/딥러닝에서는 이 목적함수를 최적화시킴으로써 학습을 진행하게 된다. 그러니, 어떤 목적함수를 지정할지, 어떤 방식으로 최소화 혹은 최대화되는 지점을 찾을 것인지가 매우 중요할 것이다.
Ex) A가 B사의 블루투스 헤드폰을 사려고 하는 경우
이때 A는 블루투스 헤드폰을 비싼 돈을 주고 사고싶어하진 않을 것이다. 배송비를 아끼려고 용산 전자상가까지 걸어간다든지, 혹은 물건값을 최대한 저렴하게 하도록 리퍼 제품을 구매한다든지 할 것임. 즉, 여기서의 배송비와 물건 값 등을 다 합친 총비용을 A는 최대한 낮추려고 할 것이다.
위에서 설명한 목적함수와 최적화의 개념을 이 예시에 적용해보면, A의 상황에서의 목적함수는 블루투스 헤드폰의 총 구매비용으로 정의되고, 이때의 A는 비용을 가장 적게 하는 것이 목적이므로 이 상황에서의 최적화는 목적함수의 최소화 문제라고 할 수 있다. 비용은 적을 수록 좋으니까.
최적화 (Optimization)
최적화란 목적함수(Objective Function)를 최대한, 혹은 최소화하는 파라미터 조합을 찾는 과정이다. 통계학의 가장 큰 갈래 중 하나인 회귀분석에서 회귀계수를 추정하는 것도 최적화 과정이다 (목적함수인 likelihood 함수를 최대화하는 베타 값을 찾는 문제 → 목적함수 최대화).
목적함수가 이익(profit), 점수(score) 등일 경우에는 최대화하는 것이 task가 될 것이고, 목적함수가 비용함수(cost), 손실함수(loss), 오차(error) 등일 경우에는 최소화 문제가 된다. 그러나 방법론 상에 큰 차이는 없다 (후에 설명할 Gradient Descent를 보면 역시 마찬가지이다).
앞서 말한 것과 같이 최적화의 예를 간단히 생각해보면 미분해서 0이 되는 지점을 찾는 것을 생각해볼 수 있으나,
1) 목적함수가 항상 미분 가능한 형태로 주어지는 것은 아님
2) Saddle Point (말안장점; 미분해서 0이 된다고 해서 무조건 최적점이 아닐 수 있다)
등의 문제가 있다. 즉 미분해서 0이 되는 지점을 찾는 것만이 최적화의 모든 것은 아니라고 할 수 있다는 것이다. (미분해서 0이 되는 지점을 찾는 것은 명시적인 해가 존재하는 경우라고 할 수 있는데 모든 함수가 명시적인 해가 존재하는 것은 아니다. 대표적으로는 Logistic Regression에서의 Likelihood Function이 그렇다. 따라서 우리는 iterative approach, 즉 반복적인 접근을 통해서 미분해서 0이 되는 지점을 approximate하는 방법을 사용한다. Gradient Descent 또한 이러한 방법 중 하나이다.)

cf.) Saddle Point (말안장점)
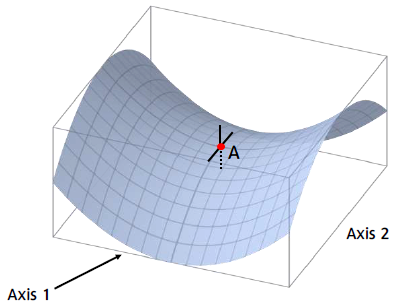
가로축을 편의상 Axis1, 세로축을 편의상 Axis2로 놓고 생각해보자. 가운데 빨간 지점을 A라고 칭한다. Axis2를 없애고 (Axis2를 찌그러뜨린다고 생각) Axis1에 대해서 보면 곡면은 아래로 볼록한 포물선의 형태(A: 최소점)를 보일 것이다. Axis1을 없애고 Axis2에 대해서만 본다면 곡면은 위로 볼록한 포물선의 형태(A: 최대점)를 보일 것이다.
가운데 점 A는 Gradient(쉽게 말하면 미분값)는 0이지만 어떻게 보느냐에 최대점, 혹은 최소점이 될 수 있다. 따라서 우리는 미분해서 0이 된다고 해서 이곳이 Globally optimal (전역 최적) 하다고 단정 지을 수 없다. 이때 A는 말안장처럼 생겼다고 하여 말안장점(Saddle Point)이라고 부른다.
경사하강법 (Gradient Descent Method)
등산을 하고 이제 하산을 해야 하는 상황이다. 현재 내 위치로부터 한 발자국을 내딛었을 때 어느 정도 높이 차이가 나는지에 대한 정보밖에 없다고 가정했을 때 산 밑으로 내려갈 수 있는 간단한 방법은 한 발자국을 내딛었을 때 가장 높이 차이가 많이 나는 방향, 즉 경사가 가장 가파른 방향으로 이동을 하는 것이다. 이러한 방식으로 최소점 (최솟값을 갖는 지점) 을 찾는 것을 Gradient Descent (경사하강법) 이라고 한다.

경사하강법은 일차 미분을 이용한 최적화 기법으로, 알고리즘은 다음과 같다.

2차 포물선에서의 경사하강법 설명은 아래의 슬라이드로 대체한다.

Gradient

(실제로 왜 그런지에 대해서는 www.princeton.edu/~aaa/Public/Teaching/ORF363_COS323/F15/ORF363_COS323_F15_Lec8.pdf 여기를 참고해보자.)
왜 우리는 그래디언트 값을 빼줄까?
위의 빨간 박스의 식을 보면 그래디언트 값을 빼주는 것을 알 수 있다. 왜 그 값을 빼주는지는 경사하강법이라는 명칭과 관련이 있다. 경사하강법은 기본적으로 목적함수 최소화에 사용된다. 따라서 Gradient가 양의 값을 갖는다면 현재 파라미터를 변수로 하는 목적 함수가 증가하고 있다는 의미이므로 parameter를 더 작은 쪽으로 움직여야 한다. 반대로 Gradient가 음의 값을 갖는다면, parameter를 더 큰 쪽으로 움직여야 할 것이다. 이에 Gradient에 learning rate(학습률, step size라고도 한다. 어느 정도 이동할 것인지를 정의함)에 곱하여 현재 파라미터 값에서 빼주는 형태로 업데이트 하는 것이다.
반대로 목적함수를 최대화하는 문제라면, Gradient값을 빼는 것이 아니라 더해주면 될 것이다. 그러나 최대화 문제는 최소화 문제에서 목적함수의 부호만 바꾸는 것으로 간단히 해결할 수 있으므로 Gradient를 더해주는 방향으로 알고리즘 상 변화를 줄 필요는 없다.

학습률 설정
경사하강법으로 최적화를 진행할 시 학습률(Learning rate) 설정 또한 매우 중요하다. 학습률이 너무 크면 한 지점으로 수렴하는 것이 아니라 발산할 가능성이 존재한다. 또한 너무 작은 학습률을 택할 때에는 수렴이 늦어진다. 또한 시작점을 어디로 잡느냐에 따라 수렴 지점이 달라진다. (의도했던 대로 전역 최소점으로 수렴할 수도 있지만, 지역 최소점으로 수렴할 가능성도 배제할 수 없다.)


Stochastic Gradient Descent (SGD)
앞서 설명한 알고리즘은 Batch Gradient Descent에 대한 설명으로, 모든 데이터에 대해서 Gradient를 계산하였다. 그러나 이는 많은 연산량을 요구한다. 따라서 한 번에 데이터 한 개만 랜덤 샘플링을 통해서 추출하고, 해당 지점의 데이터에 대해서만 그래디언트를 계산하자는 확률적 경사하강법 (Stochastic Gradient Descent)이 제안되었다.
- SGD의 장점
1) 실제 모든 데이터에 대해 Gradient 계산하는 것보다 연산 시간이 단축
2) Shooting이 일어나기 때문에 local minima에 빠질 risk가 적다.
- SGD의 단점
1) Global Optimum으로의 수렴을 역시 보장하지 못한다.
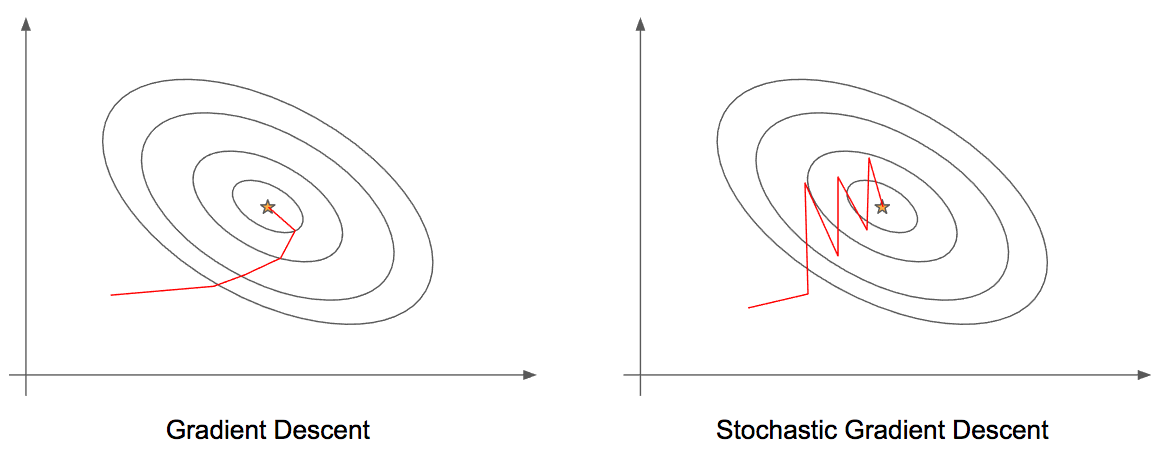
SGD는 연산량이 대폭 감소한다는 점에서 그 의의가 크지만 아무래도 한 번에 하나의 데이터 포인트만 잡아서 Gradient를 계산하면 noise가 크다 (정확도가 낮아진다). 따라서, (Batch) Gradient Descent와 Stochastic Gradient Descent 방식 두 가지의 절충안을 사용한 것이 Mini Batch Stochastic Descent이다.
이는 한번에 한 개의 데이터가 아닌, 여러 개의 데이터 포인트를 샘플링해서 Gradient를 계산하는 방법으로,
1) 한 번에 고려하는 데이터가 SGD에 비해 많아지므로 보다 정확도가 높다.
2) 모든 데이터를 한 번에 고려해서 계산하는 것이 아니므로 (Batch) Gradient Descent보다 더 효율적이다.
의 장점이 있다. 흔히 딥러닝에서 미니 배치 학습을 얘기하는 것이 바로 이를 얘기하는 것이다.
정리
최적화와 경사하강법의 개념에 대해 짧게 다루었다. 정리하자면 다음과 같다.
1) 목적함수(objective function): 최소화 혹은 최대화할 함수
2) 최적화(optimization): 목적함수를 최대화 혹은 최소화하는 것
3) 그래디언트(Gradient): 다변수 함수의 일차 편미분값으로 이루어진 벡터
4) 경사하강법(Gradient Descent): 가장 가파른 방향(Gradient가 큰 방향)으로 이동하면서 함수의 최소지점을 찾는 기법
5) 학습률(learning rate): 경사하강법에서 gradient에 곱해지는 계수로, 얼마나 이동할 것인가를 결정함.
이후의 좀 더 발전된 알고리즘에 대한 설명은
https://daebaq27.tistory.com/58
[ML/DL] 최적화(Optimization), 경사하강법 (Gradient Descent Methods) (2)
수식이 포함되어 있는 글입니다. 원활한 이해를 위해 데스크탑 모드로 전환하실 것을 권합니다. Gradient Descent First-order iterative optimization algorithm for finding a local minimum of a differentiabl..
daebaq27.tistory.com
이 글을 참고 부탁드립니다.
'DeepLearning > Basic' 카테고리의 다른 글
| [DL] ResNet의 Inspiration (4) | 2021.09.24 |
|---|---|
| [ML/DL] 최적화(Optimization), 경사하강법 (Gradient Descent Methods) (2) (0) | 2021.08.21 |
| [머신러닝/ML] 군집화 (Clustering) (0) | 2021.03.03 |
| [머신러닝/ML] 결측치 처리하는 7가지 방법 (Seven Ways to Make up Data) (0) | 2021.02.18 |
| [ML] Ensemble (1) - 보팅(Voting), 배깅(Bagging) (0) | 2021.01.28 |