군집화 (Clustering)
군집화(Clustering)는 비지도학습의 한 예시로, 어떠한 label 없이 데이터 내에서 거리가 가까운 것들끼리 각 군집들로 분류하는 것이다 (분류라고 표현했지만, 지도학습인 classification과는 다르다). 즉 데이터 내에 숨어있는 패턴, 그룹을 파악하여 서로 묶는 것이라고 할 수 있다. 만약 라벨값이 존재하는 데이터라고 하더라도, 같은 라벨 내에서도 얼마든지 다른 군집으로 묶일 가능성이 있다.
군집화 알고리즘에는 K-Means Clustering, Mean Shift, Gaussian Mixture Model, DBSCAN, Agglomerative Clustering 등이 있다. Agglomerative Clustering을 제외한 나머지 알고리즘을 정리해보고자 한다.
K-Means Clustering
K-Means Clustering
K-Means 클러스터링은 클러스터링에서 가장 일반적으로 사용되는 알고리즘으로, 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다. K-Means이므로 K개의 centroid를 지정한다. 이때 가장 가까운 포인트를 선택한다는 점에서 K-Means는 거리 기반 군집화 방법임을 알 수 있다.
군집 중심점은 선택된 포인트의 평균 지점으로 이동하고 이동된 중심점에서 다시 가까운 포인트를 선택한 후, 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행한다.

파이썬에서는 sklearn.cluster.KMeans 클래스에 구현되어 있다.
class sklearn.cluster.KMeans(n_clusters = 8, init = "k-means++",
n_init = 10, max_iter = 300, tol = 0.0001,
precompute_distances = "auto", verbose = 0, random_state = None,
copy_x = True, n_jobs = 1, algorithm = "auto") K-Means 초기화 파라미터 중 가장 중요한 파라미터는 군집화할 군집의 개수, 즉 군집 중심점의 개수를 의미하는 n_clusters이다. init은 초기에 군집 중심점의 좌표를 설정할 방식을 말하며 보통은 임의로 중심을 설정하지 않고 일반적으로 k-means++ 방식으로 최초 설정한다. max_iter는 최대 반복 횟수이며, 이 횟수 이전에 모든 데이터 중심점 이동이 없으면 종료한다.
fit() 혹은 fit_transform() 메서드를 이용해 수행하면 되며, 수행 결과로 KMeans 객체를 리턴한다. labels_와 cluster_centers_ attritubes를 통해 군집 중심점 레이블과 군집 중심점 좌표를 리턴 받을 수 있다.
클러스터링은 보통 어떤 식으로 클러스터링 되었는가를 체크하기 위해 시각화를 진행하는데, 이때 PCA 등의 차원 축소를 통해 2차원으로 매핑시킨 후 시각화를 진행하는 것이 보통이다.
Cluster Evaluation
지도학습의 경우 정답값이 존재하기 때문에 분류에는 accuracy, 회귀에는 mse 등을 활용하여 모델의 성능 평가를 쉽게 진행할 수 있다. 하지만 clustering 등의 비지도 학습의 경우에는 정답값이 없기 때문에 정량적으로 정확히 성능을 평가하는 것에는 한계가 있다. 그렇다고 해서 성능 평가 지표가 아예 존재하지 않는 것은 아니고, 군집화의 성능 평가에 있어 대표적인 방법으로 실루엣 분석(silhouette analysis)를 진행한다.
실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다. 여기서 "효율"은 다른 군집과의 거리는 떨어져 있고 동일 군집 간의 데이터는 서로 가깝게 잘 뭉쳐있음을 의미한다. 군집화가 잘 될수록 군집 내의 거리는 가깝고, 군집 간의 거리는 멀 것이다.
실루엣 분석은 실루엣 계수(silhouette coefficient)를 기반으로 하는데, 개별 데이터는 각각 실루엣 계수를 가진다. 이때 개별 데이터가 가지는 실루엣 계수는 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화되어 있고, 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지를 나타내는 지표이다.

- $i$: 각 데이터 포인트에 대한 인덱스
- $s_i$: 실루엣 계수
- $a_i$: 해당 데이터 포인트와 같은 군집 내에 있는 다른 데이터 포인트와의 거리를 평균한 값
- $b_i$: 해당 데이터 포인트가 속하지 않은 군집 내에 있는 데이터 포인트와의 거리를 군집 별로 평균을 낸 후, 그 중 작은 값 (해당 데이터 포인트와 평균적으로 가장 가까운 군집과의 거리)
$b_i - a_i$로 두 군집 간의 거리가 얼마나 떨어져 있는가의 값을 계산하며, $max(a_i, b_i)$로 나누어 $b_i - a_i$를 정규화해준다. 이렇게 나온 실루엣 계수 $s_i$는 -1과 1사이의 값을 갖게 되는데, 1로 가까워질수록 근처의 군집과 더 멀리 떨어져 있다는 것이고 0에 가까울수록 근처의 군집과 가까워진다. $s_i$가 음수인 경우 $a_i$가 $b_i$보다 값이 크다, 즉 아예 다른 군집에 데이터 포인트가 할당되었다는 의미이다.

사이킷런에서 제공되는 패키지는 다음과 같다.
- sklearn.metrics.silhouette_samples(X, labels, ...) : 각 데이터 포인트의 실루엣 계수를 계산해 반환.
- sklearn.metrics.silhouette_score(X, labels, ...) : 전체 데이터의 실루엣 계수 값을 평균해 반환. np.mean(silhouette_samples())와 동일.일반적으로 높은 silhouette_score를 가질수록 군집화가 잘되었다고 판단 가능하나 보장되는 것은 아니다.
일반적으로 좋은 군집화가 되기 위한 조건으로 제시하는 것은
- 전체 실루엣 계수의 평균값이 0~1사이의 값을 가지며, 1에 가까울 수록 좋음.
- 전체 실루엣 계수의 평균값과 더불어, 개별 군집의 실루엣 계수 평균값의 편차가 크지 않아야 함. 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않는 것이 중요함. 만약 전체 실루엣 계수의 평균값은 높지만, 특정 군집의 실루엣 계수 평균값만 유난히 높고 나머지 군집의 실루엣 계수 평균값이 낮다면 좋은 군집화라고 할 수 없을 것. (평균의 역설을 생각해보자)
최적의 군집 개수 K 결정
한편 실루엣 계수를 이용하여 최적의 군집 개수를 결정하는 것 또한 가능하다. 위와 같은 실제 군집별 실루엣 계수를 plotting하여 전체 실루엣 평균과의 비교하는 것을 통해 이루어진다. 다만 거리 계산 시 계산비용이 커지므로 샘플링을 통해 실루엣 계수를 평가하는 방법도 고려해야 한다.
cf.) elbow method
SSE(군집 내 거리의 제곱합)를 기준으로 SSE가 급격하게 낮아지는 지점을 군집의 개수 K로 지정하는 방법이다.
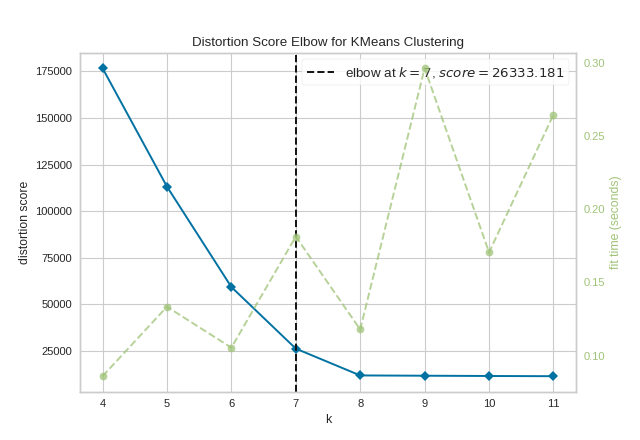
위의 그림과 같은 경우에는 SSE가 급감하는 지점인 7을 최종 K로 결정할 수 있다.
Mean Shift
평균 이동(Mean Shift)은 K-means와 유사하게 중심을 군집의 중심으로 지속적으로 움직이면서 군집화를 수행한다. 그러나 K-means 방법이 중심에 소속된 데이터의 평균 거리 중심으로 이동을 한다면, Mean Shift는 중심을 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킨다는 점에서 그 차이가 있다.

Mean Shift는 특정 대역폭(bandwidth;region of interest)을 가지고 최초의 확률 밀도 중심 내에서 데이터의 확률 밀도가 더 높은 곳으로 중심을 이동한다. (centroid-based algorithm라고 한다)
Mean Shift는 데이터 간의 거리가 아닌 데이터의 분포도를 이용해 군집 중심점을 잡는다. 군집 중심점은 데이터 포인트가 모여 있는 곳이라는 아이디어에 착안한 것이며, 이를 위해 확률 밀도 함수를 이용한다. 일반적으로 확률 밀도 함수를 찾기 위해 KDE(Kernel Density Estimation)를 이용한다. Mean Shift 알고리즘은 임의의 포인트에서 시작해 데이터 내의 확률 밀도 peak 포인트를 찾을 때까지 KDE를 반복적으로 적용하며 군집화를 수행한다.
Mean Shift 알고리즘은 K-Means와 다르게 군집의 개수를 지정할 필요가 없다. 다만 bandwidth의 크기에 따라 알고리즘 자체에서 군집의 개수를 최적화하므로, bandwidth의 최적화가 필요하다 (이쯤되면 군집의 개수를 지정할 필요는 없지만 어차피 똑같은 게 아닌가 하는 생각은 든다).
사이킷런에서는 Mean Shift clustering이 MeanShift 클래스에 구현이 되어 있으며, bandwidth 최적화를 위한 estimate_bandwidth() 또한 API로 제공한다.
from sklearn.cluster import MeanShift, estimate_bandwidth
## MeanShift 클래스
MeanShift(bandwidth = .9) # bandwidth를 파라미터로 갖는다.
## estimate_bandwidth
best_bw = estimate_bandwidth(X, quantile = .2) # Data와 quantile를 인자로 받는다.estimate_bandwidth()의 경우에는 quantile을 인자로 받는데, 이 quantile은 커널 밀도 추정 시 사용되는 것이며 자세한 것은 www.inflearn.com/questions/23299 이 글을 참고하자.
Mean Shift 알고리즘은 데이터셋의 형태를 특정 형태로 가정한다든가, 특정 분포도 기반의 모델로 가정하지 않기 때문에 좀 더 유연한 군집화가 가능하다는 이점을 갖는다. 이상치에 좀 더 robust하며 미리 군집의 개수를 사전에 결정할 필요가 없다는 점 또한 Mean Shift 알고리즘의 장점이다. 그러나 알고리즘의 수행 시간이 오래 걸리며, bandwidth의 크기가 군집화에 미치는 영향이 매우 크다는 점의 단점 또한 존재한다. 이와 같은 특징 때문에 일반적으로 Mean Shift 클러스터링은 특정 개체를 구분하거나 움직임을 추적하는 등 컴퓨터 비전 영역에서 더 잘 사용된다고 한다.
Gaussian Mixture Model (GMM)
GMM
GMM clustering은 데이터를 K개의 가우시안 분포가 혼합되어 있다고 간주하는 것에서부터 출발한다. 즉 현실에 존재하는 복잡한 데이터 분포가 K개의 가우시안 분포를 혼합하여 표현하자는 아이디어이다. 혼합 가우시안 분포 (Gaussian Mixture)에서 개별 유형의 가우시안 분포 K개를 추출한 후, 각 데이터가 어느 분포에 속하는지를 추정함으로써 클러스터링이 이루어진다. 즉 K개의 개별 가우시안 분포가 각 K개의 클러스터가 되는 것이다. 이때 이 K는 사용자가 지정하는 하이퍼 파라미터이다. GMM은 분포를 가정 및 추정하여 군집화 하는 방식으로 확률 기반 군집화 알고리즘 중 하나이다.

GMM에서는 두 가지의 추정이 필요하다.
- 개별 가우시안 분포 곡선을 추정 (즉 정규분포 모수인 $\mu, \sigma$ 를 추정. 정확히는 이때의 모수는 행렬이다.)
- 현재 데이터가 어느 분포에 속할 것인지 그 확률 분포를 추정
모수 추정 시 EM 알고리즘을 적용하고, 더 자세한 설명은 untitledtblog.tistory.com/133 을 참고하자. 한편 GMM은 사이킷런에 GaussianMixture 클래스로 구현이 되어 있다. GaussianMixture의 인자 중 n_components는 위에서 언급한 K이다. (개별 가우시안 분포의 개수 = 군집의 개수)
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components = 3) # Gaussian Mixture 객체 생성GMM은 수행 시간이 오래 걸린다는 단점이 존재하지만 K-Means 대비 보다 유연하게 다양한 데이터셋에 적용될 수 있다는 점에서 이점을 갖는다.
GMM vs. K-means
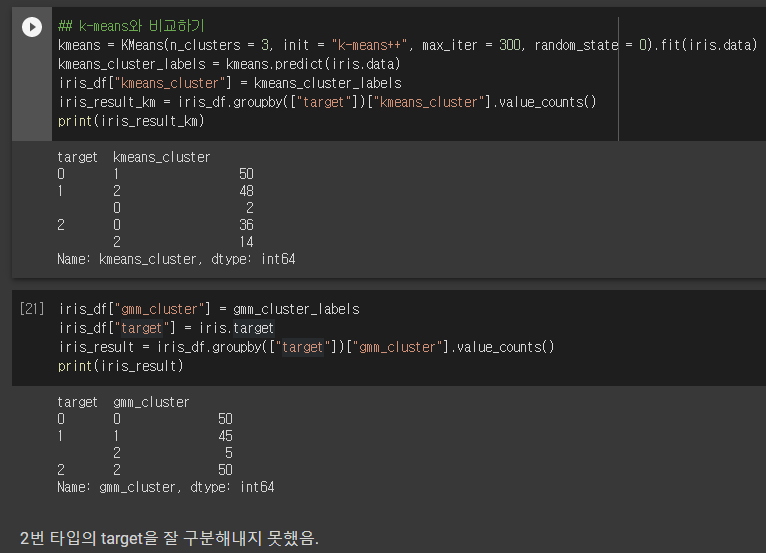
iris 데이터에 GMM과 K-Means를 각각 적용했을 때, K-Means의 군집화 결과가 GMM보다 조금 안좋음을 파악할 수 있다. 이는 알고리즘 측면에서 GMM이 더 뛰어나서라기보다는 데이터셋의 특성이 K-Means보다 GMM에 더 효과적이기 때문이다. K-means는 평균 거리 중심으로 중심을 이동하면서 군집화를 수행하는 방식이기 때문에 개별 군집 내의 데이터가 원형으로 흩어져 있는 경우에 매우 효과적으로 군집화가 수행될 수 있다. 반면 GMM은 타원형으로 길게 늘어진 데이터 군집화에 보다 효과적으로 적용된다. iris 데이터는 타원형태로 길게 뻗어 있는 데이터이기 때문에 K-means가 효과적으로 적용되기 어렵고, GMM이 효과적으로 적용될 수 있었던 것이다.

보다 자세한 설명은 towardsdatascience.com/gaussian-mixture-models-d13a5e915c8e 이 글을 참고하자.
DBSCAN
DBSCAN은 밀도 기반 클러스터링 방법이다. 보다 기하학적으로 복잡하게 분포된 데이터셋에도 효과적인 군집화가 가능함. DBSCAN을 구성하는 가장 중요한 두 가지 파라미터는 epsilon으로 표기하는 주변 영역과 epsilon 주변 영역에 포함되는 최소 데이터의 개수 min_points이다.
DBSCAN 알고리즘


- 입실론 주변 영역 (epsilon; eps): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 최소 데이터 개수 (min points): 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
- 핵심 포인트 (Core Point): 주변 영역 내에 최소 데이터 개수 이상의 타 데이터를 가지고 있는 데이터
- 이웃 포인트 (Neighbor Point): 주변 영역 내에 위치한 타 데이터
- 경계 포인트 (Border Point): 주변 영역 내에 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않지만 핵심 포인트를 이웃 포인트로 가지고 있는 데이터
- 잡음 포인트 (Noise Point): 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않으며, 핵심 포인트도 이웃 포인트로 가지고 있지 않은 데이터

DBSCAN은 밀도 기반이기 때문에 다른 밀도로 구성된 클러스터, 혹은 기하학적으로 복잡한 구조를 가지는 데이터와 같은 경우에도 적용할 수 있다는 점, Mean Shift 알고리즘보다 이상치에 더 robust하다는 점(Mean Shift는 심한 극단값을 만나면 다른 cluster로 분류한다), 임의의 모양과 임의의 사이즈의 클러스터로도 군집화가 가능하다는 점에서 이점을 갖지만 반대로 DBSCAN이 제대로 적용되는 경우가 흔치 않다는 단점 또한 존재한다.
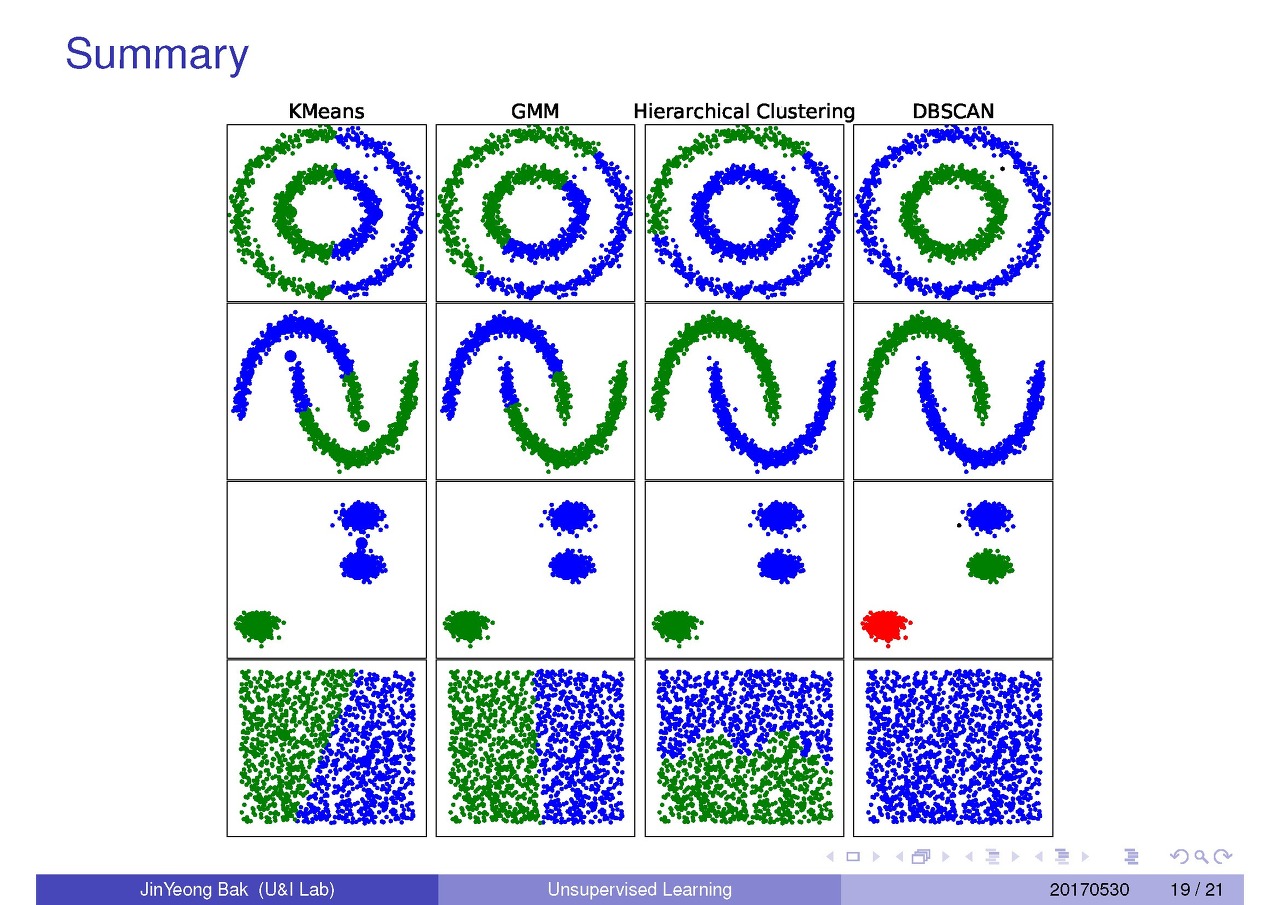
사이킷런에는 DBSCAN 클래스로 구현되어 있다.
from skelarn.cluster import DBSCAN
dbs = DBSCAN(eps = .6, min_samples = 8, metric = "euclidean")
dbs_labels = dbs.fit_predict(X) # DBSCAN 클러스터 라벨링 객체 생성
[reference]
1. untitledtblog.tistory.com/133
2. 파이썬 머신러닝 완벽 가이드 ch7.
3. michigusa-nlp.tistory.com/27
[figure 출처]
1. Gaussian Mixture: untitledtblog.tistory.com/133
2. DBSCAN 시각화: deep-eye.tistory.com/36
3. GMM vs K-Means: amueller.github.io/COMS4995-s18/slides/aml-16-032118-clustering-and-mixture-models/#1
'DeepLearning > Basic' 카테고리의 다른 글
| [DL] ResNet의 Inspiration (4) | 2021.09.24 |
|---|---|
| [ML/DL] 최적화(Optimization), 경사하강법 (Gradient Descent Methods) (2) (0) | 2021.08.21 |
| [머신러닝/ML] 결측치 처리하는 7가지 방법 (Seven Ways to Make up Data) (0) | 2021.02.18 |
| [ML/DL] 최적화(Optimization), 경사하강법 (Gradient Descent Algorithms) (2) | 2021.02.04 |
| [ML] Ensemble (1) - 보팅(Voting), 배깅(Bagging) (0) | 2021.01.28 |