Object Detection 성능의 평가
모델이 얼마나 객체 탐지를 성공적으로 수행했는가는 두 가지 측면에서 살펴볼 수 있다.
1) 얼마나 잘 탐지하는가?
2) 얼마나 빠르게 탐지하는가?
얼마나 잘 탐지하는가는 Accuracy의 측면으로, mAP로 흔히 평가한다. 얼마나 빠르게 탐지하는가는 inference time을 얼마나 단축시키는가의 측면으로, 모델의 효율성 등과 연관되며 이는 FPS로 흔히 평가한다.
얼마나 잘 탐지하는가
Precision and Recall
- Recall = TP / (TP+FN) = TP / # of ground truths
- Precision = TP / (TP + FP) = TP / # of predictions
간단히 말하면 Recall은 actual == True인 경우 중에, 예측값도 True인 경우의 비율이라고 할 수 있고, Precision은 True라고 예측한 값 중에 실제값도 True인 경우의 비율이라고 할 수 있다. Recall과 Precision은 언뜻 비슷하게 보이지만, Recall과 Precision이 꼭 같은 방향으로 간다는 보장은 없다. 오히려 Recall과 Precision 모두 최고치로 높이는 것은 사실상 불가능하다. 이를 Recall - Precision Trade off라고 부른다. (이 두가지를 어느 정도 높은 수준에서 끊을 수 있도록 threshold를 설정하는 것이 중요한데, 이 경우 precision-recall curve를 그려서 확인한다. 혹은 f1 score를 성능 평가 지표를 활용하는 방법도 있다.)
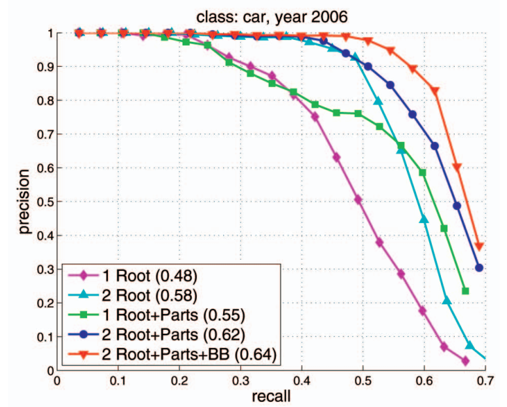
이 두 가지가 불균형한 경우를 살펴보자. 높은 Recall값을 가질 때 낮은 Precision을 가지는 경우는 Positive Sample의 경우에 Positive라고 잘 예측하지만 반대로 Negative Sample 또한 Positive라고 예측을 해버리는 경우이다. 실제로 target값의 분포가 불균형할 때 이러한 경우가 많이 발생한다. Precision이 높지만 Recall 값이 낮은 경우는 실제 Positive라고 예측한 sample의 경우에는 거의 정확하지만, 실제 positive라고 예측하는 경우 자체가 적은 것을 의미한다.
위의 두 지표는 mAP를 이해하는 데 기반이 된다.
cf.) Confusion Matrix
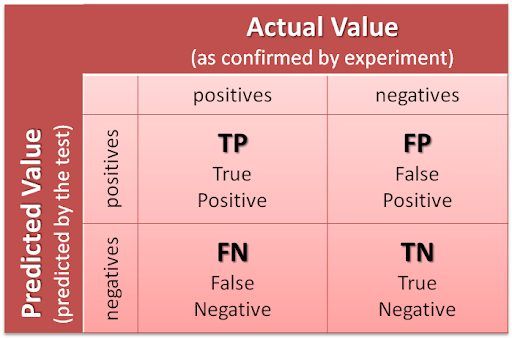
classification task 수행 시 실제 값과 예측값을 비교하는 table을 confusion matrix라고 한다.
- True Positive (TP): 실제값이 True일 때 예측값도 True인 경우
- False Postiive (FP): 실제값이 False일 때 예측값은 True인 경우
- True Negative (TN): 실제값이 False일 때 예측값도 False인 경우
- False Negative (FN): 실제값이 True일 때 예측값은 False인 경우
앞의 True / False는 실제값과 예측값이 일치하는지 여부, 뒤의 Positive / Negative는 예측값이라고 생각하면 쉽다.
AP (Average Precision)
Precision-Recall curve는 하나의 알고리즘 성능을 파악하는 데에는 용이하지만 (보통 이러한 curve는 threshold 등을 결정하는 데에 사용하는 듯), 서로 다른 알고리즘의 성능을 정량적으로 비교하는데에는 불편함이 있다. 따라서 우리는 알고리즘 간 성능 비교를 용이하게 하기 위해 precision-recall curve를 하나로 요약한 값인 AP를 사용한다. 이때 AP는 각 threshold에서의 precision의 가중합을 의미하며, 이때의 가중치는 이전 threshold와 현재의 threshold 에서의 recall 값의 차이이다. 결국에 AP는 Precisions의 Average를 대표하는 값으로 볼 수 있다. 수식으로 표현하면 다음과 같다.

index가 의미하는 바는 threshold임에 주의하자.
수식을 자세히 살펴보면, AP는 결국 Precision-Recall curve에서의 커브 아래 면적이다. (ROC 커브에서의 auc score와 같은 맥락)
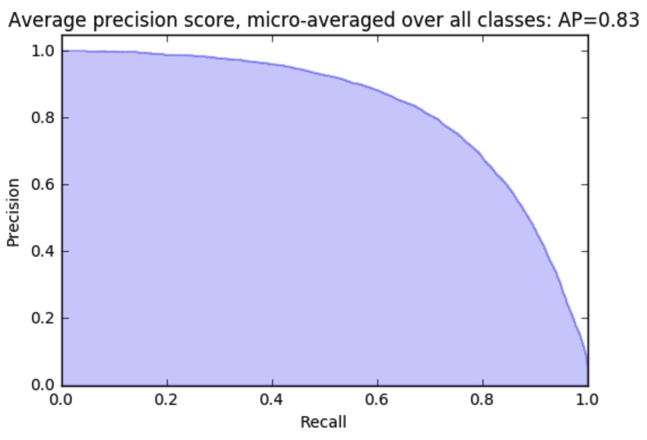
AP가 클수록(high performance w.r.t both metrics) 성능이 좋은 알고리즘이라고 할 수 있다.
IoU (Intersection over Union)
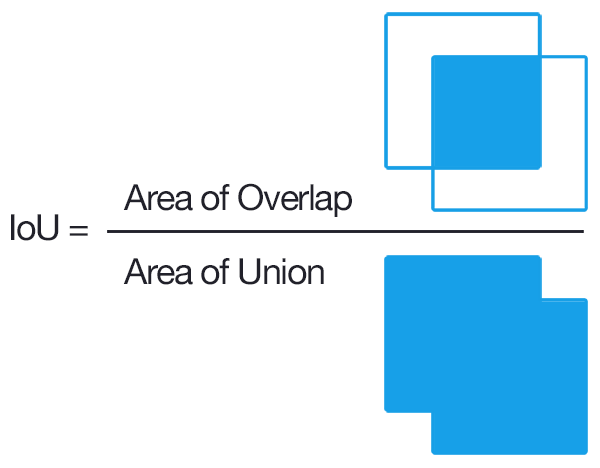
IoU는 실제 bounding box와 예측된 bounding box 사이의 합집합과 교집합의 비율을 의미한다. 해당 값이 높을 수록 예측이 잘되었다고 말할 수 있다. 설정한 threshold보다 IoU값이 높거나 같으면 해당 predicted bounding box는 positive, 즉 객체가 존재한다고 label된다. 반대로 threshold보다 낮다면 해당 bounding box는 negative로 label된다.

위의 그림을 예시로 들어보자. threshold가 0.7이라고 가정하면 A, B는 객체가 존재하지 않는다고 label될 것이고 C는 box 내에 객체가 존재한다고 label될 것이다. theshold를 0.5로 낮춘다면 A, C는 이전과 결과가 같지만 B는 객체가 존재한다고 label될 것이다.
정리하자면 Bounding Box의 classification은 위와 같이 IoU를 계산한 후, 그에 대한 thresholds를 바탕으로 이루어진다고 볼 수 있다. 이러한 라벨링 결과를 바탕으로 AP와 같은 성능평가 지표를 계산하는 것이다.
mAP (mean Average Precision)
AP는 여러 알고리즘 간의 성능 비교가 가능한 알고리즘 성능 평가 지표이다. obejct detection에서는 하나의 객체(binary class)만을 탐지하는 것이 아닌, 여러 객체를 탐지하는 것이므로(multi-class) AP를 모든 class에 대해 계산할 필요가 있다. 이때 mAP는 AP를 class에 대해 average한 결과이다. 각 class 별로 AP를 계산하여 해당 class에 대해 Prediction 값의 정확도를 구한 후, 이를 모든 class에 대해 평균을 내어 해당 모델이 모든 클래스에 대해 어느 정도의 탐지 정확도를 기록하는지 판단할 수 있다. 아래는 mAP의 수식이다. k는 class에 대한 index이고, n은 이미지 셋 내의 전체 객체 클래스의 개수이다.

위의 수식은 뜯어보면 정확히 2번의 summation이 이루어지게 된다. 1) $AP_k$ 산출 시 2) mAP 산출 시
얼마나 빠르게 탐지하는가
객체 탐지가 얼마나 정확하게 이루어지는가도 중요하지만, 동시에 객체 탐지가 얼마나 빠르게 이루어지는가? 또한 중요하다. 즉 inference time이 중요하다는 의미이다.
FPS (Frames Per Second)
이 때, fps라는 개념을 통해 얼마나 빠르게 객체 탐지가 이루어지는가를 판단할 수 있다. fps는 흔히 frame per second로서 한 초당 얼마나 많은 frame으로 구성되어 있는가를 의미한다. fps가 높을수록, 즉 1 second 내에 많은 frame을 보여주는 영상일 수록 끊김없이 더 실제에 가깝게 표현된 영상이라고 할 수 있다.
object detection에서의 fps는 초당 detection하는 비율을 의미한다. 예를 들어 20fps는 초당 20 frame을 detection함을 의미한다. fps가 높을 수록 해당 모델의 detection이 빠르게 이루어지고 30fps 이상을 기록한다면 Real-Time 수준의 detection이 이루어지고 있다. 즉, 초당 연속적인 frame을 30개 이상 처리할 수 있다면 real time object detection이라고 할 수 있다. real time object detection의 경우에 사람은 끊기지 않고 연속적으로 detection이 이루어진다고 인식한다. (별다른 이상함을 못느끼는 자연스러운 상태)

위의 그림을 보면, efficientdet의 경우에는 fps가 낮을 때는 AP가 높게 기록되지만, fps가 40 이상이 되는 경우에 AP가 급감하는 것을 볼 수 있다 (추론 속도를 포기한다면, 높은 정확도를 보여줌). 반면 yolov4 모델은 높은 수준의 fps와 AP를 두루두루 보여주고 있음을 알 수 있다. 어느 정도의 빠른 inference time과 AP를 동시에 보장하고 있음을 알 수 있다.
reference
1. kharshit.github.io/blog/2019/09/20/evaluation-metrics-for-object-detection-and-segmentation
2. 89douner.tistory.com/80
3. blog.paperspace.com/mean-average-precision/
4. gaussian37.github.io/ml-concept-ml-evaluation/#average-precision-ap-1
figure 출처
1. medium.com/@awabmohammedomer/confusion-matrix-b504b8f8e1d1
2. gaussian37.github.io/ml-concept-ml-evaluation/#average-precision-ap-1
3. towardsdatascience.com/how-to-evaluate-a-classification-machine-learning-model-d81901d491b1
'DeepLearning > Computer Vision' 카테고리의 다른 글
| [Object Detection] Focal Loss (0) | 2021.09.30 |
|---|---|
| [DL/CV] NN interpolation의 backward propagation (0) | 2021.09.29 |
| [Object Detection] Image Annotation Formats (0) | 2021.03.17 |
| [Object Detection] RefineDet 리뷰 (0) | 2021.03.01 |
| [Object Detection] Faster R-CNN 논문 리뷰 (0) | 2021.03.01 |